1 Ciencia abierta y reproducible
En esta sección se aprenderá sobre la ciencia abierta reproducible. Conoceremos una serie de herramientas disponibles para reproducir flujos de trabajos científicos, entre los más populares están Python, Jupyter, Bash, GitHub entre otros.
1.1 ¿Qué es la Ciencia abierta reproducible?
La ciencia abierta reproducible involucra hacer disponible para todos, los métodos científicos, datos y resultados. Puede dividirse en:
Transparencia en la colección de los datos, procesamiento, métodos de análisis y la obtención de resultados.
Publicar los datos y los métodos de procesamiento asociados.
Hacer transparente la comunicación de resultados.
La ciencia reproducible es cuando cualquiera puede entender y replicar los pasos de un análisis, aplicarlos a los mismos o nuevos datos. La ciencia abierta es también soportada por la colaboración. Ambos, los resultados reproducibles que se originan en flujos de trabajos reproducibles, permiten que el trabajo se comparta y se pueda colaborar con otros, así como abiertamente publicar tus datos y flujos de trabajo para contribuir al conocimiento.
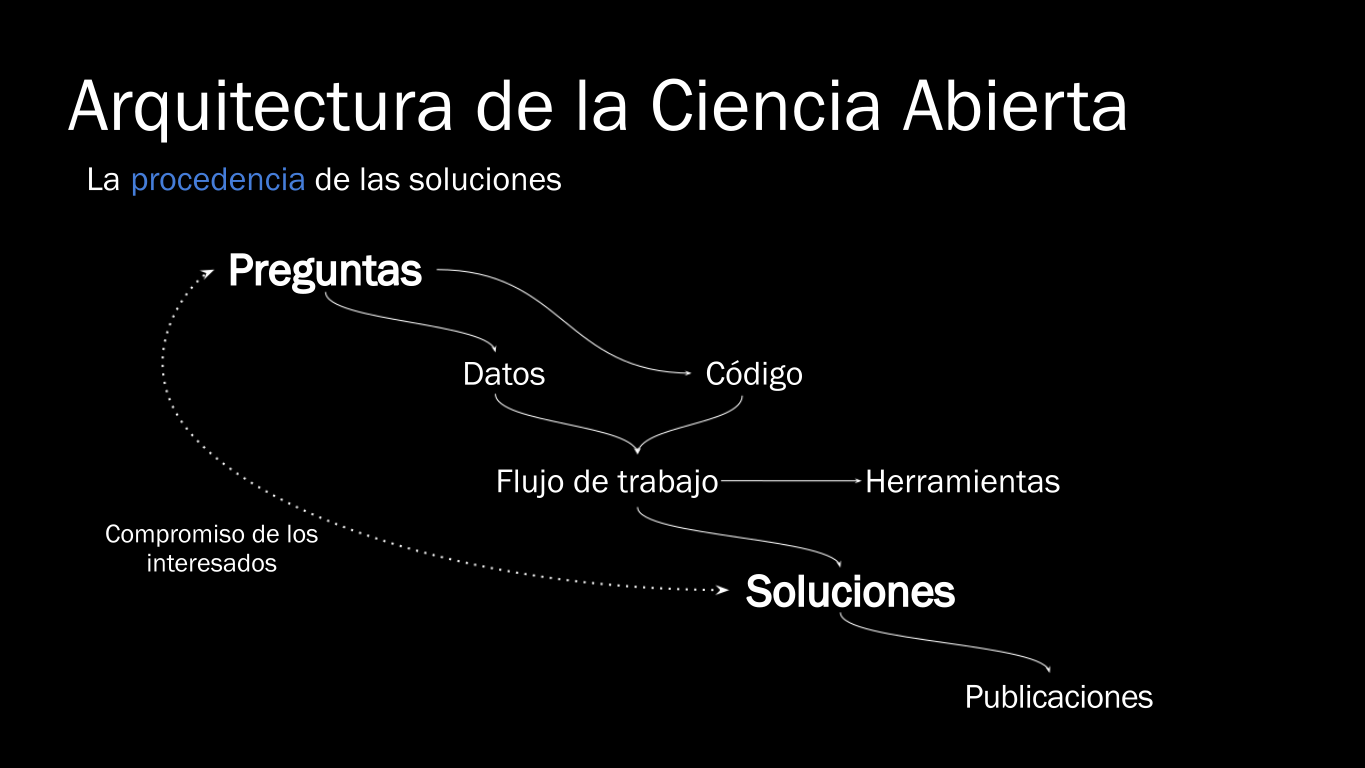
¿Cómo hacer tu trabajo más abierto y reproducible?
Lo siguiente son algunas cosas que se podrían hacer para hacer de tu trabajo una instancia más abierta y reproducible. Es probable que algunas tareas sean muy demandantes, aunque no es necesario hacerlas todas, con solo empezar, es una buena señal.
Usar programación científica para procesar los datos
La programación científica permite la automatización de tareas, lo cual facilita que los flujos de trabajo puedan ejecutarse fácilmente y ser replicados. Al contrario, si usamos un flujo de trabajo basado en un Graphic User Interface, GUI (Interfaz Gráfica de Usuario en español), va a requerir interacción de pasos manuales para el proceso, lo cual lo hace más demandante de tiempo para la reproducción. Si puedes usar un lenguaje como R o Python, entonces las personas podrán acceder a tus métodos. Por el contrario, si usas un programa con licencia pagada, toda la gente que no pueda acceder a esa licencia quedará excluida de reproducir tu flujo de trabajo.
Ejemplo de un flujo de trabajo basado en GUI:
Se quiere analizar al día de hoy, la evolución del vigor vegetal mensual para un bosque nativo que se quemó el año 2017. Como resultado, usted deberá procesar las bandas del R (Rojo) y NIR (Infrarrojo Cercano) de las imágenes para calcular el NDVI mensual usando la calculadora del GUI con el programa que esté utilizando. ¿Cuántas interacciones tendría que realizar? (24 interacciones, suponiendo dos imágenes por mes). Piense en un ejemplo de GUI como Excel, Word, o un programa para la creación de figuras.
Use los principios FAIR para mejorar la reproducción de los proyectos
Asegúrate que los datos usados en tu proyecto estén en línea con los principios Findable, Accessible, Interoperable, Reusable FAIR (Wilkinson et al. 2016)1, de manera que sean fáciles de encontrar, accesibles, interoperables, reusables, y que exista documentación de como acceder a ellos y lo que contienen.Los principios FAIR también se extienden más allá de los datos crudos y se aplican a las herramientas y flujos de trabajos que son usados para procesar y crear nuevos datos.
Protege tus datos crudos
No modifiques (o sobre escribas) los datos crudos. Mantén los datos separados de los resultados, de manera que sea más fácil volver a correr los métodos o flujos, las veces que lo necesites. Es más fácil si organizas tus datos en directorios o carpetas, donde puedas separar resultados de los datos crudos, referencias, documentos u otros insumos que estés usando.
Documenta tus flujos de trabajo
Lo básico es incluir comentarios en el código del flujo de trabajo, que expliquen los paso a paso de tu flujo. La documentación puede incluir usar herramientas como Jupyter Notebook o RMarkdown, para incluir un texto narrativo en formato Markdown que sea intercalado junto con el código, proporcionando una explicación del flujo.
Diseña flujos de trabajo que sean fáciles de recrear
Es más fácil diseñar flujos de trabajo que sean factibles de reproducir por otras personas, intentando seguir:
Al inicio del código, lista todos los paquetes y dependencias que se requieren para correr el flujo de trabajo (en archivos Jupyter o Markdown).
Organiza el código en secciones o bloques que se relacionen, e incluye comentarios para explicar el código.
Crea ambientes reproducibles para flujos de trabajo en Python, usando por ejemplo, Conda Environments.
1.2 Herramientas necesarias para ciencia abierta y reproducible
Para implementar los flujos de trabajos en la ciencia abierta, serán necesarios herramientas que nos ayuden a documentar, automatizar y compartir nuestro trabajo. Por ejemplo, puede ser necesario documentar como se colectaron los datos (protocolos), como los datos fueron procesados y que tipo de análisis se usaron para resumir los datos. Mientras existen muchas herramientas que soportan la ciencia abierta reproducible, acá nos enfocaremos en: Bash, Python y Jupyter Notebooks.
Usa herramientas de programación científica para automatizar flujos de trabajo
Mucha gente comienza a usar datos en herramientas como Excel (para datos tabulares) o ArcGIS (datos espaciales), los cuales poseen GUIs. Estas pueden ser útiles para aprender tempranamente, ya que poseen interfaces visuales que pueden ser menos agobiantes para los iniciados. Sin embargo, a medida que el tamaño o volumen de los datos que se está trabajando aumenta, generalmente es un desafío para las herramientas basadas en GUI poder manejarlos. Otras herramientas basadas en GUIs requieren de pasos individuales que son manualmente implementados (a menos que se escriban macros o pequeños scripts de automatización). Esto hace que el flujo de trabajo sea difícil de reproducir. Algunas herramientas como Excel o ArcGIS requieren de una licencia, lo cual limita quien puede acceder a tus datos, y además podría limitar incluir el flujo de trabajo en la nube o en un entorno remoto.
La programación científica usando lenguajes de libre acceso como R, Python o Julia, es una forma efectiva y eficiente para comenzar a construir flujos de trabajos que pueden ser reproducibles y, además fácilmente compartidos.
En este curso nos centraremos en Python que es un lenguaje de programación libre, abierto y gratuito, que puede ser descargado por cualquiera para ser usado. Adicionalmente, se ha convertido en uno de los lenguajes más populares y demandados en el mercado del trabajo (ejemplo de PyQGIS para desarrollar plugins y herramientas dentro del entorno de QGIS).
Use Bash para la manipulación y manejo de archivos, carpetas y ambientes de trabajo
El Bash es el programa primario que los computadores usan para recibir órdenes (comandos), retornando información producida por la ejecución de estos comandos (salidas). Estos comandos pueden ser entrados usando un terminal (conocido también como Interfaz de líneas de comando CLI), que será el que revisemos.
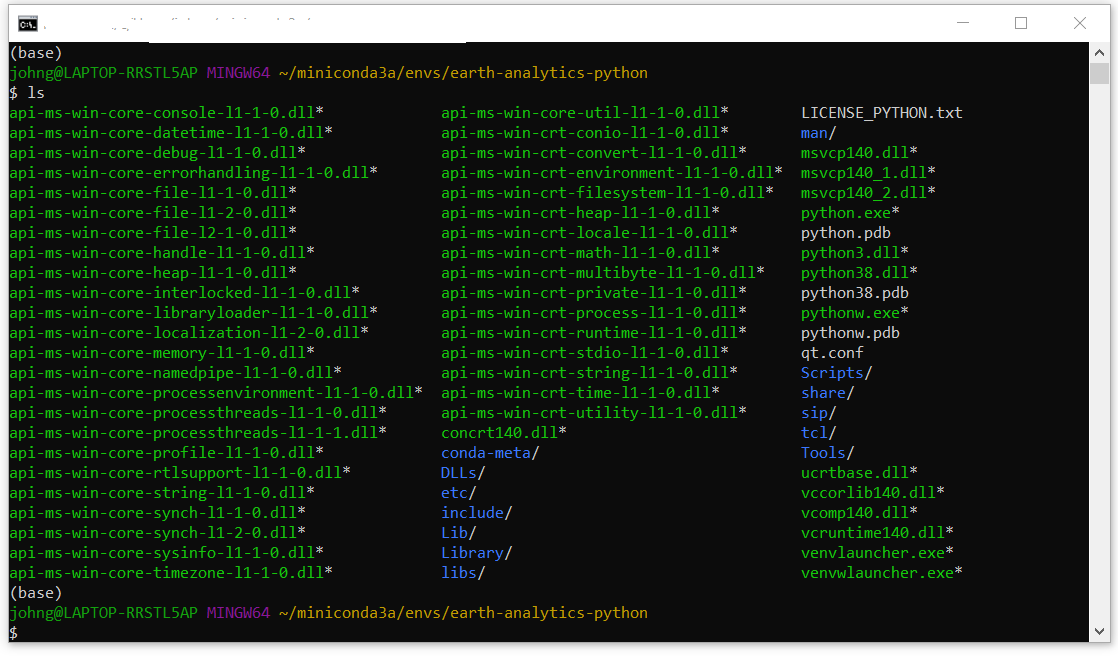
ls.
El usar Bash nos ayudará a:
Acceder y manejar archivos y directorios
Trabajar eficientemente con muchos archivos y directorios a la vez
Ejecutar programas desde directorios específicos como Jupyter Notebook para realizar programación interactiva.
Usar comandos reusables para estas tareas a través de múltiples sistemas operativos (Windows, Mac, Linux).
Bash también es importante si se requiere trabajar en máquinas remotas de alto rendimiento, de cluster o en la nube.
El proyecto Jupyter
Es un esfuerzo de open source que soporta la programación interactiva. Soporta varios lenguajes como R, Python, Julia. Hay tres herramientas que se deberían conocer:
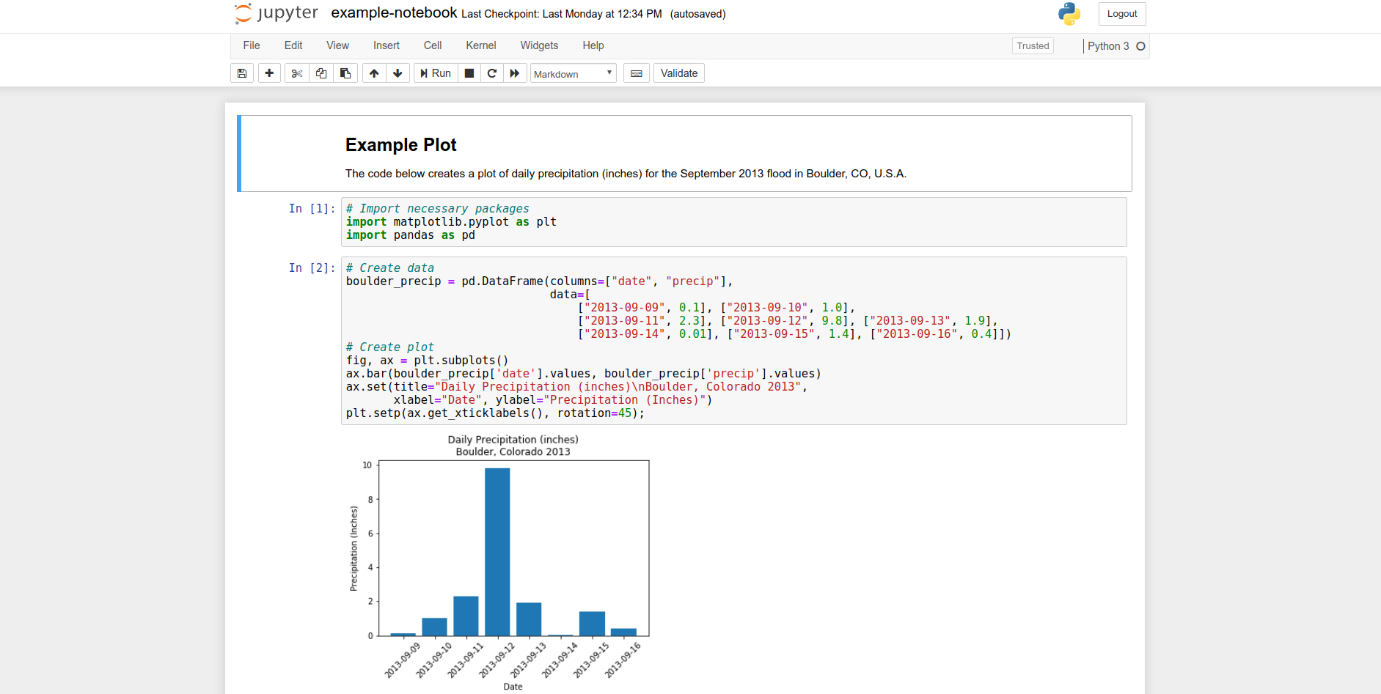
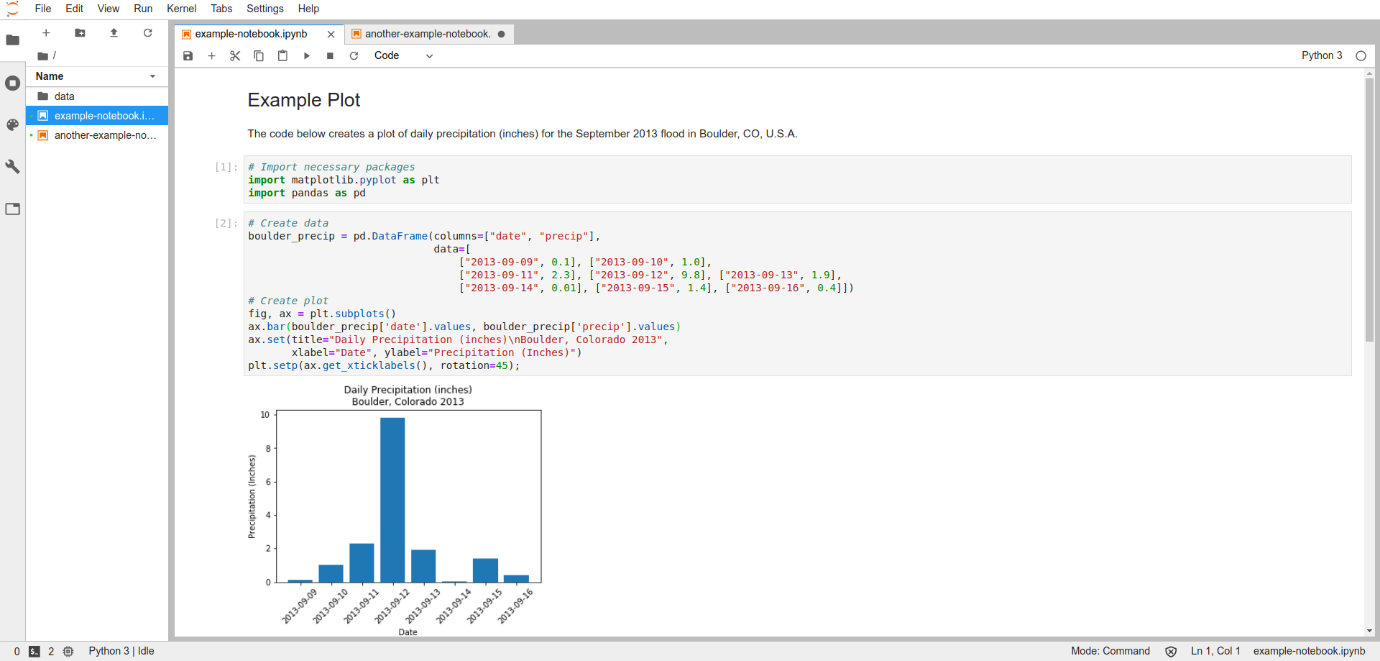
Jupyter Notebook: es una aplicación basada en un navegador que permite crear, compartir documentos que contienen código, ecuaciones, visualizaciones y texto narrativo. Los usos incluyen: limpieza de los datos y transformación, simulación numérica, modelamiento estadístico, visualización y mucho más.
- JupyterLab: es un ambiente interactivo de desarrollo para Jupyter Notebook, códigos y datos. JupyterLab es flexible, se puede configurar para soportar un amplio rango de flujos de trabajo. JupyterLab es extensible y modular, se pueden escribir plugins que agreguen nuevos componentes que se integren con los existentes.
- JupyterHub: es una versión multi-persona de Jupyter Notebook que puede correr en un servidor.
Organiza y documenta flujos de trabajos usando archivos de Jupyter Notebook
Conectar tu flujo de trabajo completo, incluyendo el acceso a los datos, el procesamiento y los resultados, es una parte importante de la ciencia abierta reproducible. Los archivos Jupyter pueden ayudar a conectar tu flujo de trabajo, permitiendo escribir y ejecutar código interactivamente, así como también organizar tu código con documentación y resultados dentro de los archivos Jupyter. Además, puedes exportar los archivos Jupyter como HTML y PDF para un fácil intercambio. Escribir y organizar el código Python dentro de los archivos Jupyter, ayuda a soportar la ciencia reproducible, a través de la documentación de los datos de entrada, los códigos para análisis, la visualización y los resultados. Todo esto dentro de un archivo es más fácil de compartir con otros.
1.2.1 ¿Cómo organizar tu proyecto?
En esta sección vamos a aprender la importancia de describir de forma adecuada los nombres de los archivos y directorios, de manera que sean fáciles de leer por la computadora. Además, revisaremos algunas buenas prácticas para organizar proyectos de ciencia reproducible.
Organiza tu directorio de proyecto para hacerlo fácil de entender
Cuando se trabaja con los datos de un proyecto, a menudo hay una gran cantidad de archivos que es necesario almacenar en el computador. Los archivos pueden ser del tipo:
Archivos de datos crudos o en bruto
Archivos de datos procesados
Códigos y scripts
Salidas como figuras o tablas
Escritos asociados con tu proyecto (notas, manuscritos, informes, etc.)
La organización propuesta te ayudará a ahorrar tiempo, y que el proyecto sea más usable y reproducible.
La importancia de los nombres de directorios y archivos
A medida que vas creando nuevos directorios y archivos en el computador, considera usar una convención que los haga más fáciles de encontrar y también entender lo que esos archivos son o contienen. Es una buena práctica usar archivos y directorios que:
Sean legibles por humanos, usando nombres que claramente describan que contienen los directorios o los archivos (códigos, datos, salidas, figuras, etc.).
Sean legibles por máquinas, evitando usar caracteres extraños o espacios. En lugar de espacios, se pueden usar (
-) o (_) para separar las palabras, haciéndolas más fáciles de leerlas o separarlas.Ordenables, es una buena costumbre lograr incluir algunos caracteres en los nombres de los archivos y directorios, que permitan ordenarlos fácilmente (
01-enero.tif,02-febrero.tif,03-marzo.tif)
Con estas simples reglas no solo se estará ayudando a organizar los directorios y los archivos, sino que también se estará ayudando a implementar nombres que sean legibles por máquinas, los cuales pueden ser fácilmente consultados o analizados usando programación científica u otra forma de automatización.
Buenas prácticas para proyectos de ciencia abierta reproducible
- Use convenciones consistentes en el nombramiento
Los nombres de archivos que pueden ser leídos por las máquinas, permitirá que tus directorios sean fácilmente manipulables y manejados por códigos. Por ejemplo, si quieres escribir un script en que el que se procesen un grupo de imágenes ordenadas por fecha. Sería necesario incluir algún tipo de información de la fecha en el nombre del archivo, de preferencia al inicio del nombre. De esta manera será fácil procesarlos con el código que escribas. Veamos un mal ejemplo.

Por otro lado, veamos un buen ejemplo, incluso a veces solo basta con indicar un carácter ordinal.


Si tus archivos o directorios tienen patrones o reglas identificables, esto les permitirá que sean más manipulables, de esta manera será más fácil automatizarlos a través de tareas. Otras buenas prácticas para los nombres de los archivos y directorios en los proyectos pueden ser:
Evita espacios en los nombres de los archivos y directorios. Los espacios en los nombres de archivos pueden dificultar cuando se hacen flujos automáticos.
Usa guiones para separar palabras, los guiones o underscores pueden hacer más fácil la creación de nombres expresivos. Estos caracteres son también fáciles de procesar por los códigos.
Considera la necesidad de enumerar los archivos si tienes la necesidad de ordenarlos.
- Se consistente cuando nombres archivos, usa letras minúsculas
A veces es tentador usar letras minúsculas o mayúsculas, sin embargo, el estilo de las letras puede causar problemas en la ejecución de los códigos, especialmente si los códigos son compartidos en distintos sistemas operativos. Veamos un ejemplo puntual.

Si queremos llamar al primer archivo sería fácil usando Python:
Es muy probable que este llamado sirva para ambos archivos en varios sistemas operativos. Sin embargo, el siguiente llamado:
Solo funcionará en Windows, es muy probable que, en Mac o Linux, solo llamé al archivo que cumpla exactamente con los caracteres. Para evitar eso simplemente use letras minúsculas en todas las convenciones para nombres de archivos y directorios.
- Organiza tus directorios de proyectos para hacerlos fáciles de encontrar los datos, códigos y resultados
Un directorio de proyecto es más que guardar un montón de archivos, considéralo una organización de elementos que se ajuste a tu proyecto. Enumera los directorios que forman parte de tu flujo de trabajo.

Los números al inicio de cada directorio te permiten ordenar los directorios en una manera que será fácil analizarlos con códigos. Además, cada directorio tiene un nombre expresivo que permite conocer fácilmente su contenido. Separar los elementos del proyecto hace más fácil poder encontrarlos. Esto es especialmente útil cuando requieras volver al proyecto después de un largo tiempo sin verlo para actualizar algunas cosas. Ayuda además a las colaboraciones. No hay una organización perfecta, por lo tanto, lo mejor es probar con alguna organización que funcione y mantenerla. Abajo hay un ejemplo de estructuras, ¿cuál de ellas funciona mejor?

- Use nombres de archivos y directorios que sean significativos
Usar nombres significativos son útiles para describir el contenido de los archivos y los directorios. El uso de nombres expresivos hace más fácil el escaneo del directorio del proyecto y entender fácilmente donde están almacenadas las cosas, y lo que los directorios o archivos contienen.

- Documente el proyecto con un archivo de lectura
Hay muchas maneras de documentar un proyecto, sin embargo, un archivo de léeme al nivel más alto del proyecto se usa como una convención estándar. El archivo léeme es un archivo de texto que describe los datos, el software y las herramientas usadas para procesar los datos en tu proyecto. El léeme también puede describir los archivos asociados y las convenciones de nombres. Puede ser usado también para describir las abreviaciones usadas, o las unidades, entre otras cosas.
- No use formatos propietarios
Los formatos propietarios son formatos que requieren de una herramienta especifica (o licencia) para abrirlos. Los ejemplos más simples son Excel (.xls) o Word (.doc). Estos formatos pueden cambiar con el tiempo, a medida que van saliendo nuevas versiones (.xlsx o .docx). En algunos casos estos formatos son sistemas operativos específicos (ejemplo, la mayoría de los usuarios Linux no usan herramientas de Microsoft). Cuando escojas archivos de formatos para tus proyectos, piensa si vas a tener licencias en el futuro para acceder a esos archivos, o si otros tendrían. Si usas formatos que no dependen de licencias o sistemas operativos como .csv o .txt, permites que más personas tengan acceso a tus archivos, incluyéndote a ti, que quizás a futuro no tengas las licencias necesarias para abrir tus propios archivos.
Wilkinson, M., Dumontier, M., Aalbersberg, I. et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci Data 3, 160018 (2016). https://doi.org/10.1038/sdata.2016.18↩︎