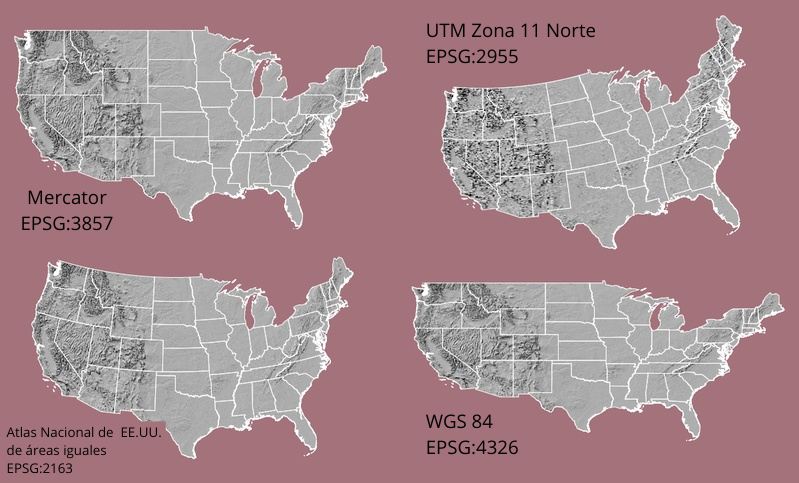
En este capítulo aprenderemos cómo procesar datos vectoriales, incluyendo cómo reproyectar datos a un sistema de coordenadas de referencia, recortar datos a una extensión específica, disolver y unir geometrías.
Después de terminar los estudiantes podrán:
Identificar el CRS del dataset espacial y reproyectarlo a otro.
Recortar espacialmente los vectores de acuerdo a la extensión espacial de un polígono usando Geopandas.
Unir y disolver geometrías dependiendo de sus atributos o fronteras.
Trabajando con datos espaciales que poseen distintos sistemas de referencia
A veces deseamos plotear juntos dos datasets (caminos y parcelas) y en algunas ocasiones esto no resulta, aun sabiendo que ambos datos están en la misma posición geográfica.
Es muy común que se obtengan datos espaciales desde distintas fuentes y que esos datos cubran diferentes extensiones espaciales. Este tipo de datos espaciales se encuentran a menudo en diferentes Sistemas de Referencia de Coordenadas (CRS, por sus siglas en inglés). Existen algunas razones porque los datos están en distintos CRS:
Los datos están almacenados en un CRS particular usado por un proveedor de datos, el cual podría ser institución u organismo estatal.
Los datos están almacenados en un CRS particular que es apropiado para una zona o región. Por ejemplo, en Chile se usa el huso 19 Sur para una parte del país desde la zona central al norte y el huso 18 Sur para la zona sur.
Históricamente, debido a la falta de sistematización en los sistemas de referencia, en 1985 se formó el Grupo Europeo de Estudio del Petróleo (European Petroleum Survey Group, EPSG por sus siglas en inglés), con el objetivo de definir y compartir definiciones geodésicas. Desde entonces, se ha convertido en el estándar para describir diversos CRS, asignando a cada uno un código específico. Para más información, puede visitar esta página web.
A modo de ejemplo, se mostrará Estados Unidos en distintos sistemas de referencia (con su respectivo código EPSG):
Para el seguimiento de la clase, se trabajará con las siguientes capas:
Provincias censales de Chile continental.
Caminos dentro de las regiones de Los Lagos, Los Ríos y Araucanía.
Área de Influencia (AOI) cercana al sector de Paillaco.
Masas lacustres de la región de Los Ríos.
Áreas pobladas de la región de Los Ríos.
Toponímia de la región de Los Rios.
De este modo, cargamos las librerías:
# Importando los paquetes necesarios
import os
os.environ['USE_PYGEOS'] = '0'
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import geopandas as gpd
import earthpy as et
import pandas as pd
import warnings
warnings.filterwarnings('ignore', 'GeoSeries.notna', UserWarning)
sns.set_style("white")
sns.set(font_scale = 1.5)
/usr/share/miniconda/envs/tallerpython/lib/python3.10/site-packages/earthpy/__init__.py:7: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
from pkg_resources import resource_string
Aquí, se puede ver el paquete seaborn, el cual provee un lenguaje de alto nivel para personalizar dibujos y gráficos hechos con Matplotlib. En este caso, set_style establece un fondo blanco a cada gráfico y set(fontscale = 1.5) aumenta el tamaño del texto en un 50%. Si desea conocer más acerca de este paquete, puede visitar su documentación oficial.
warnings en este caso se emplea para ignorar los warnings sobre geometrías pérdidas/vacías (missing/empty).
Como se ha hecho a lo largo del curso, tendremos que cambiar nuestro directorio de trabajo al de "earth-analytics" y procedemos con la descarga.
# Configura el directorio de trabajo
os.chdir(os.path.join(et.io.HOME, 'earth-analytics',
"data", "earthpy-downloads"))
print(os.getcwd())
# Descarga la data
et.data.get_data(url = "https://figshare.com/ndownloader/files/49767573")
Downloading from https://figshare.com/ndownloader/files/49631469
Extracted output to C:\la\ruta\hasta\process_vector
Podemos examinar el archivo que acabamos de descargar a traves de os.listdir(), el cual muestra los archivos o directorios de una dirección.
os.listdir("process_vector/")
['area_influencia', 'caminos', 'datos_censales', 'los_rios']
Podemos notar que los archivos mostrados en la consola son directorios, ya que no muestran extensión alguna.
Primero, se cargarán las capas descritas anteriormente. Para cargar estos archivos podemos ayudarnos de os.path.join(), el cual interpretará los argumentos proporcionados como directorios o archivos.
# Importando los datos. Arma el string de la ruta
caminos_path = os.path.join("process_vector", "caminos",
"caminos.shp")
# Usa la ruta para leer el archivo
caminos = gpd.read_file(caminos_path)
aoi_path = os.path.join("process_vector", "area_influencia",
"aoi.shp")
aoi = gpd.read_file(aoi_path)
provincias_path = os.path.join("process_vector", "datos_censales",
"censo_provincias.shp")
provincias = gpd.read_file(provincias_path)
masas_lacustres_path = os.path.join("process_vector", "los_rios",
"masa_lacustres_lr.shp")
masas_lacustres = gpd.read_file(masas_lacustres_path)
toponimia_path = os.path.join("process_vector",
"los_rios",
"toponimia_lr.shp")
toponimia = gpd.read_file(toponimia_path)
areas_pobladas_path = os.path.join("process_vector", "los_rios",
"areas_pobladas_lr.shp")
areas_pobladas = gpd.read_file(areas_pobladas_path)
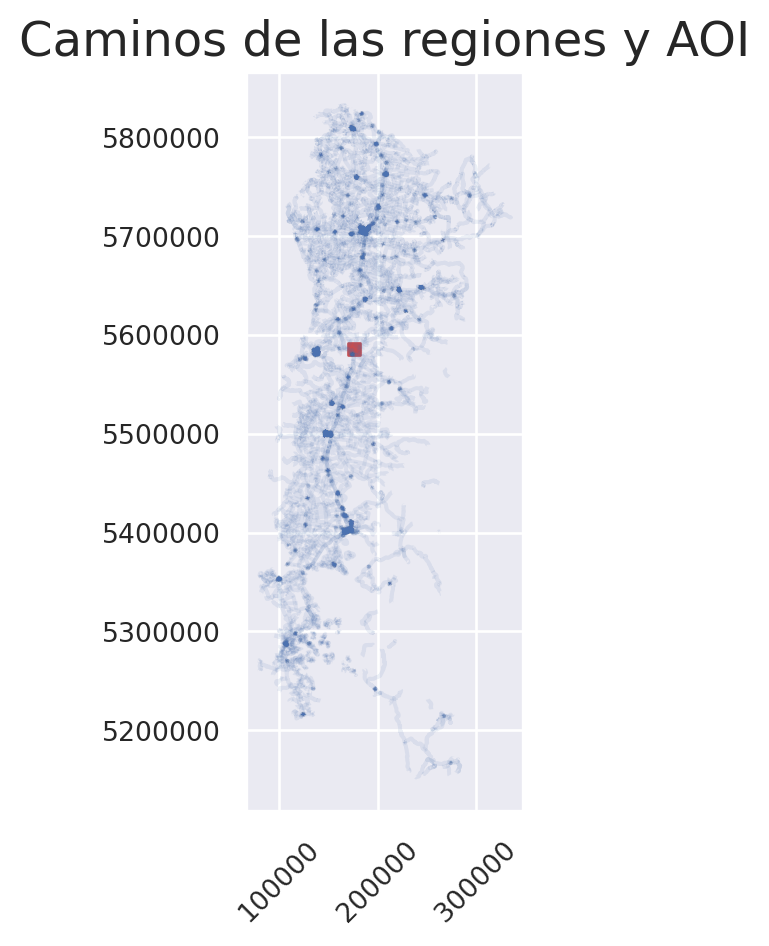
Intentemos graficarlas ambas capas junto con Matplotlib:
fig, ax = plt.subplots()
caminos.plot(ax = ax, # Definimos el ax
alpha = 0.1) # Con 10% de transparencia
aoi.plot(ax = ax, # Definimos el mismo axes
color = 'red',
edgecolor = "red", # Especificamos el color del borde
linewidth = 1) # grosor del borde
ax.tick_params(axis = "x", # definimos el tamaño y orientacion del eje x para fines esteticos
labelsize = 10,
labelrotation = 45)
ax.tick_params(axis = "y", # misma definicion de arriba
labelsize = 10)
ax.ticklabel_format(style='plain') # Muestra todos los números del eje.
ax.set_title("Caminos de las regiones y AOI")
plt.show()
¿Qué es lo que ocurre? Para revisar lo que ocurre en este gráfico podemos ver si comparten el mismo sistema de coordenadas:
# Imprime el CRS de ambas layers
print(f"El CRS de los caminos es: {caminos.crs}, mientras que el del AOI es {aoi.crs}")
El CRS de los caminos es: EPSG:32719, mientras que el del AOI es EPSG:4326
Podemos observar que ambas capas no tienen el mismo CRS.
Reproyectando datos vectoriales
Si deseamos plotear los datos en una misma figura, entonces ellos necesitan estar en el mismo CRS. Es posible cambiar el CRS al que se desea a través de la reproyección de un CRS a otro. Esto se puede usando el método:
to_crs(crs-especifico-acá)
Adicionalmente, los CRS pueden ser especificados usando su código EPSG como el siguiente:
epsg=4326
La función .to_crs() requiere de dos entradas:
El nombre del objeto que se quiere transformar
El CRS al cual se quiere transformar el objeto. Esto puede estar en un formato de string EPSG o de project4 (por ejemplo, el CRS obtenido desde otro objeto espacial).
Es importante mencionar que cuando reproyectamos los datos, los estamos modificando. De esta forma estamos introduciendo alguna incerteza en nuestros datos. Mientras esta incerteza es ligeramente menos importante en los datos vectoriales que en los raster, es necesario considerarla. Por otra parte, si solo se reproyecta para crear un mapa base, no es importante.
En este caso, reproyectaremos la capa de AOI al CRS de las carreteras:
# Asignamos la reproyección a un nuevo objeto
aoi_reproyec = aoi.to_crs(epsg = 32719)
fig, ax = plt.subplots()
caminos.plot(ax = ax,
alpha = 0.1)
aoi_reproyec.plot(ax = ax,
color = 'r',
edgecolor = "r",
linewidth = 1)
ax.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax.tick_params(axis = "y",
labelsize = 10)
ax.ticklabel_format(style='plain')
ax.set_title("Caminos de las regiones y AOI")
plt.show()
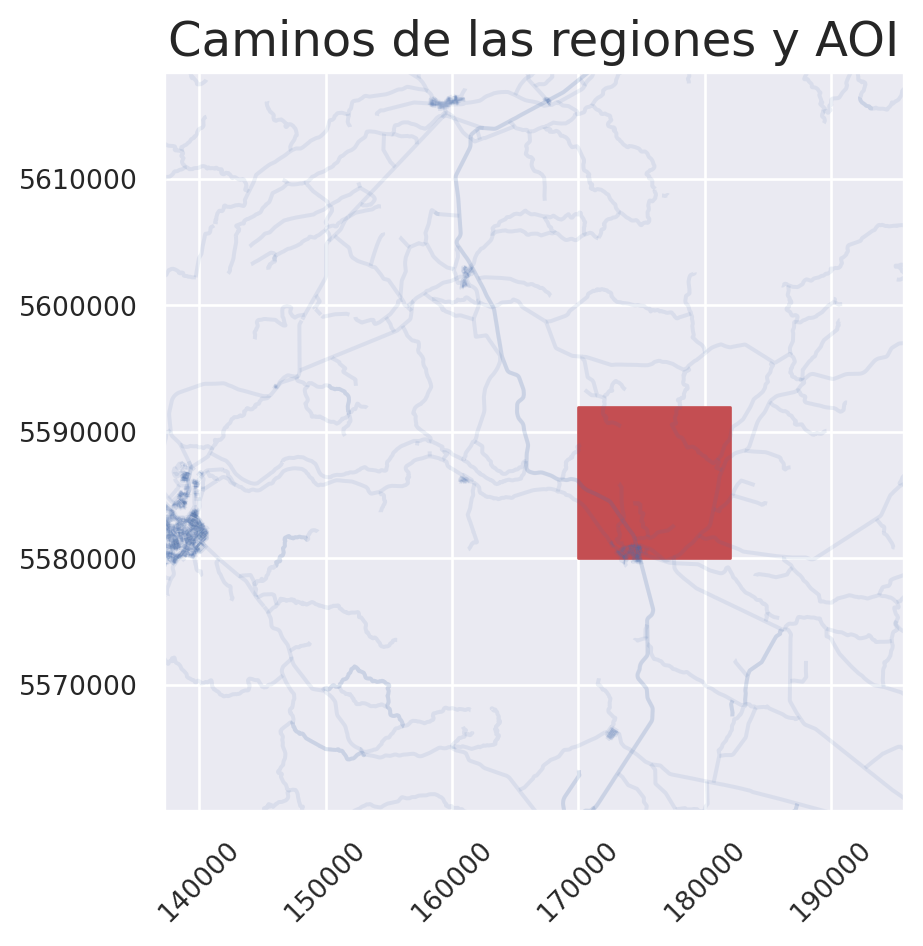
Sin embargo, no podemos visualizar el AOI correctamente debido a la gran extensión de las carreteras. Para solucionarlo, podemos reducir la extensión de nuestro mapa o recortar los caminos que están dentro de este. En el primer caso, es necesario especificar los límites del gráfico mediante .set(), definiendo los rangos tanto para el eje x (xlim) como para el eje y (ylim) utilizando listas.
fig, ax = plt.subplots()
caminos.plot(ax = ax,
alpha = 0.1)
aoi_reproyec.plot(ax = ax,
color = 'r',
edgecolor = "r",
linewidth = 1)
ax.set(xlim = [137192, 195778], # Limites en el eje X
ylim = [5560030, 5618481]) # Limites en el eje Y
ax.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax.tick_params(axis = "y",
labelsize = 10)
ax.ticklabel_format(style='plain')
ax.set_title("Caminos de las regiones y AOI")
plt.show()
En el otro caso, deberemos cortar la capa de caminos.
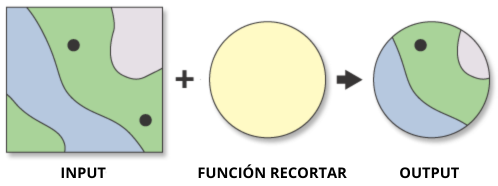
Recortando datos vectoriales
Cuando se hace un recorte espacial lo que se hace es remover datos que están afuera de la extensión de interés. Esto significa que el dataset recortado será más pequeño (tendrá una extensión espacial menor) que los datos originales. Esto implica que los objetos en los datos, tales como líneas o polígonos, serán cortados basados en la extensión del objeto que se usa para recortar.
¿Cuándo es necesario hacer un recorte de los datos?
Existen varias razones por las cuales se puede necesitar hacer un recorte:
Se tienen más datos de los que en realidad se necesitan. Por ejemplo, se tienen datos que están fuera de la zona de estudio y por lo tanto no se necesita procesarlos. Recortar los datos a la extensión de la zona de estudio, los hará mas pequeños y más fáciles de manejar.
Si se tienen datos fuera de la zona de estudio y se recortan, los análisis se pueden hacer solo en esa región, de esta manera no será necesario volverlos a recortar cuando se haga, por ejemplo, análisis estadísticos.
Cuando los datos se ploteen, solo se verá la extensión de interés.
Geopandas utiliza la función .clip(), para recortar puntos, líneas y polígonos. Esta función necesita de tres argumentos:
gdf =: layer de vectores (puntos, líneas y polígonos) para ser recortados.
mask =: un layer de polígonos que será usado para recortar a gdf. La geometría de máscara es disuelta como una geometría e intersectada con el gdf.
keep_geom_type =: si es True, el método .clip() solo conservará las geometrías que coinciden con el tipo de las geometrías originales del GeoDataFrame. Esto es útil para evitar resultados con geometrías mixtas, como puntos o líneas que puedan surgir tras el recorte de polígonos. Aunque las geometrías mixtas se mencionen, estas no pueden darse en un shapefile, sin embargo, si pudiesen encontrarse en algunos GeoDataFrames que proviene de GeoJSON o de bases de datos espaciales. En cambio, si es False el método devolverá todas las geometrías resultantes del recorte, incluso si se generan geometrías de diferente tipo. Por ejemplo, al recortar polígonos, si solo una parte de ellos se encuentra dentro del área de recorte, el resultado podría incluir líneas o puntos, en lugar de solo polígonos.
.clip() recortará los datos a la extensión del polígono que se seleccionó. Si hay múltiples polígonos utilizados como mask, la función recortará los datos a la extensión total de todos los polígonos que estén dentro de mask.
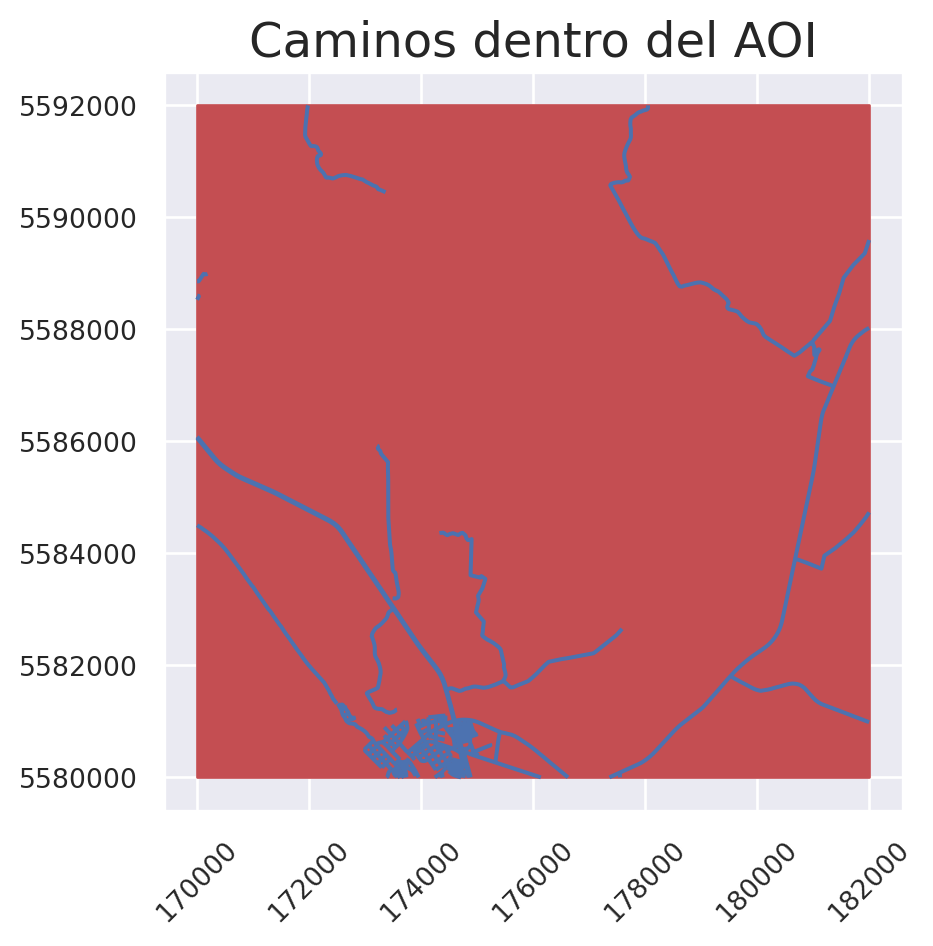
caminos_clip = gpd.clip(gdf = caminos,
mask = aoi_reproyec,
keep_geom_type = True)
Por ende, el gráfico quedaría de la siguiente manera:
fig, ax = plt.subplots()
aoi_reproyec.plot(ax = ax,
color = 'r',
edgecolor = "r",
linewidth = 1)
caminos_clip.plot(ax = ax)
ax.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax.tick_params(axis = "y",
labelsize = 10)
ax.ticklabel_format(style='plain')
ax.set_title("Caminos dentro del AOI")
plt.show()
Elementos dependientes de la geometría
Al realizar una transformación espacial, la geometría de los elementos en la capa vectorial original se modifica (por ejemplo, una línea de 50 km puede reducirse a 2 km). Como resultado, la capa generada hereda la información de su capa original. Esto no afecta a los identificadores (como el nombre, código, región, etc.), pero sí influye en los atributos que dependen de la geometría, como la longitud de una línea o el área de un polígono. Si trabajamos con estos atributos y nuestra capa ha sido transformada, es necesario actualizarlos para garantizar un análisis adecuado de los datos.
Comparemos, por ejemplo, los mismos objetos de la capa de caminos originales y recortados a través de su longitud (representada por long_mt en la tabla de atributos). Para realizar esta comparación, podemos usar los índices de la capa recortada para filtrar la capa original mediante .index:
Index([22613, 28408, 22637, 22317, 22481, 22487, 22989, 22618, 22146, 22122,
...
22458, 28212, 28213, 15715, 15716, 28221, 22268, 22998, 22123, 22946],
dtype='int64', length=151)
Con este índice, podemos especificar qué objetos queremos analizar en la capa caminos (accediendo a través de .loc):
caminos.loc[caminos_clip.index].head()
| 22613 |
None |
T-55 |
3 |
Pavimento |
Rural |
14 |
48344.188 |
LINESTRING (177547.522 5580083.153, 177548.163... |
| 28408 |
None |
T-45 |
3 |
Pavimento |
Rural |
14 |
57062.004 |
MULTILINESTRING ((231020.565 5576451.454, 2310... |
| 22637 |
None |
T-39 |
3 |
Pavimento |
Rural |
14 |
52159.321 |
LINESTRING (177552.776 5580087.15, 177603.908 ... |
| 22317 |
Juan Pablo Ii |
T-39 |
3 |
Pavimento |
Rural |
14 |
4080.054 |
MULTILINESTRING ((213237.786 5606223.739, 2132... |
| 22481 |
None |
None |
9 |
None |
Urbano |
14 |
666.008 |
LINESTRING (174368.442 5580089.113, 174382.774... |
| 22613 |
None |
T-55 |
3 |
Pavimento |
Rural |
14 |
48344.188 |
LINESTRING (177547.522 5580083.153, 177548.163... |
| 28408 |
None |
T-45 |
3 |
Pavimento |
Rural |
14 |
57062.004 |
LINESTRING (179528.503 5581813.067, 179577.69 ... |
| 22637 |
None |
T-39 |
3 |
Pavimento |
Rural |
14 |
52159.321 |
LINESTRING (177552.776 5580087.15, 177603.908 ... |
| 22317 |
Juan Pablo Ii |
T-39 |
3 |
Pavimento |
Rural |
14 |
4080.054 |
MULTILINESTRING ((174579.511 5581027.476, 1745... |
| 22481 |
None |
None |
9 |
None |
Urbano |
14 |
666.008 |
LINESTRING (174368.442 5580089.113, 174382.774... |
Si comparamos los primeros cinco objetos de ambos GeoDataFrames, vemos que corresponden a los mismos. Aunque presentan la misma longitud, esto puede resultar engañoso. Por eso, sumaremos la longitud de los caminos originales y recortados para verificar si hay alguna diferencia. Para la capa original, mostramos los objetos de interés, seleccionamos la columna long_mt y sumamos sus valores:
suma_caminos_original = caminos.loc[caminos_clip.index]["long_mt"].sum()
En el caso de la capa recortada, creamos una nueva columna (long_mt_nuevo) y calculamos la longitud de la geometría usando .length:
# Creamos la nueva columna y calculamos la longitud a través de la geometría
caminos_clip["long_mt_nuevo"] = caminos_clip.geometry.length
suma_caminos_cortados = caminos_clip["long_mt_nuevo"].sum()
Finalmente, comparamos los resultados:
print(f"La suma de los caminos orignales es de {suma_caminos_original} mt, mientras que de los datos cortados son {suma_caminos_cortados} mt \n"
f"En este caso, se tiene una diferencia de {round(suma_caminos_original - suma_caminos_cortados, 2)} mt.")
La suma de los caminos orignales es de 516478.073 mt, mientras que de los datos cortados son 96581.12315544183 mt
En este caso, se tiene una diferencia de 419896.95 mt.
Disolviendo datos vectoriales
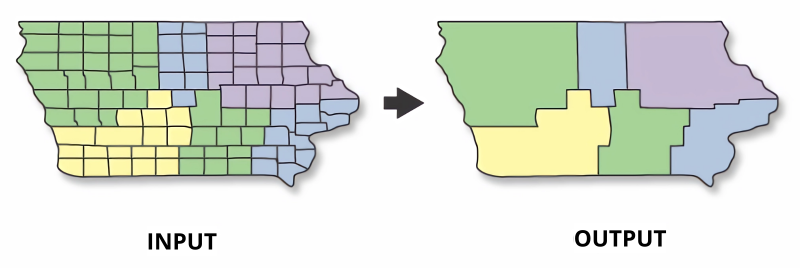
Usar disolver en el contexto de la información geográfica es adecuado cuando se desea simplificar o agrupar elementos espaciales que comparten un atributo común. Esta operación permite combinar varias entidades en una sola, reduciendo la cantidad de geometrías y optimizando el análisis espacial. Por ejemplo, si se tienen polígonos que representan diferentes áreas de una misma categoría, como zonas de un uso de suelo específico, disolver estas áreas en una sola geometría mejora la visualización, facilita el análisis estadístico y reduce el tamaño de los archivos, lo que puede aumentar la eficiencia de los procesos.
Para disolver un GeoDataFrame, GeoPandas ocupa el método dissolve(). Algunos de sus parámetros son:
by =: La columna o columnas cuyos valores definen los grupos a disolver. Por defecto es None, interpretando todo el GeoDataFrame como un único objeto.
aggfunc =: Función de agregación para manipular datos asociado a cada grupo. Tiene distintas combinaciones como funciones o strings asociados a una función.
En este caso, tenemos un mapa censal con las provincias de Chile (cargado anteriormente). Este presenta la siguiente estructura:
<class 'geopandas.geodataframe.GeoDataFrame'>
RangeIndex: 55 entries, 0 to 54
Data columns (total 18 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 REGION 55 non-null object
1 PROVINCIA 55 non-null object
2 NOM_REGION 55 non-null object
3 NOM_PROVIN 55 non-null object
4 TOTAL_VIVI 55 non-null int64
5 PARTICULAR 55 non-null int64
6 COLECTIVAS 55 non-null int64
7 TOTAL_PERS 55 non-null int64
8 HOMBRES 55 non-null int64
9 MUJERES 55 non-null int64
10 DENSIDAD 55 non-null float64
11 INDICE_MAS 55 non-null float64
12 INDICE_DEP 55 non-null float64
13 IND_DEP_JU 55 non-null float64
14 IND_DEP_AD 55 non-null float64
15 SHAPE_Leng 55 non-null float64
16 SHAPE_Area 55 non-null float64
17 geometry 55 non-null geometry
dtypes: float64(7), geometry(1), int64(6), object(4)
memory usage: 7.9+ KB
Por ejemplo, si quiseramos tener un mapa de Chile por regiones, podríamos disolver provincias a través de su atributo REGION:
regiones = provincias.dissolve(by = "REGION",
aggfunc = "first")
Además, si el argumento by = no se menciona, se puede crear un mapa Nacional de Chile continental, como se muestra a continuación:
chile = provincias.dissolve(aggfunc = "first")
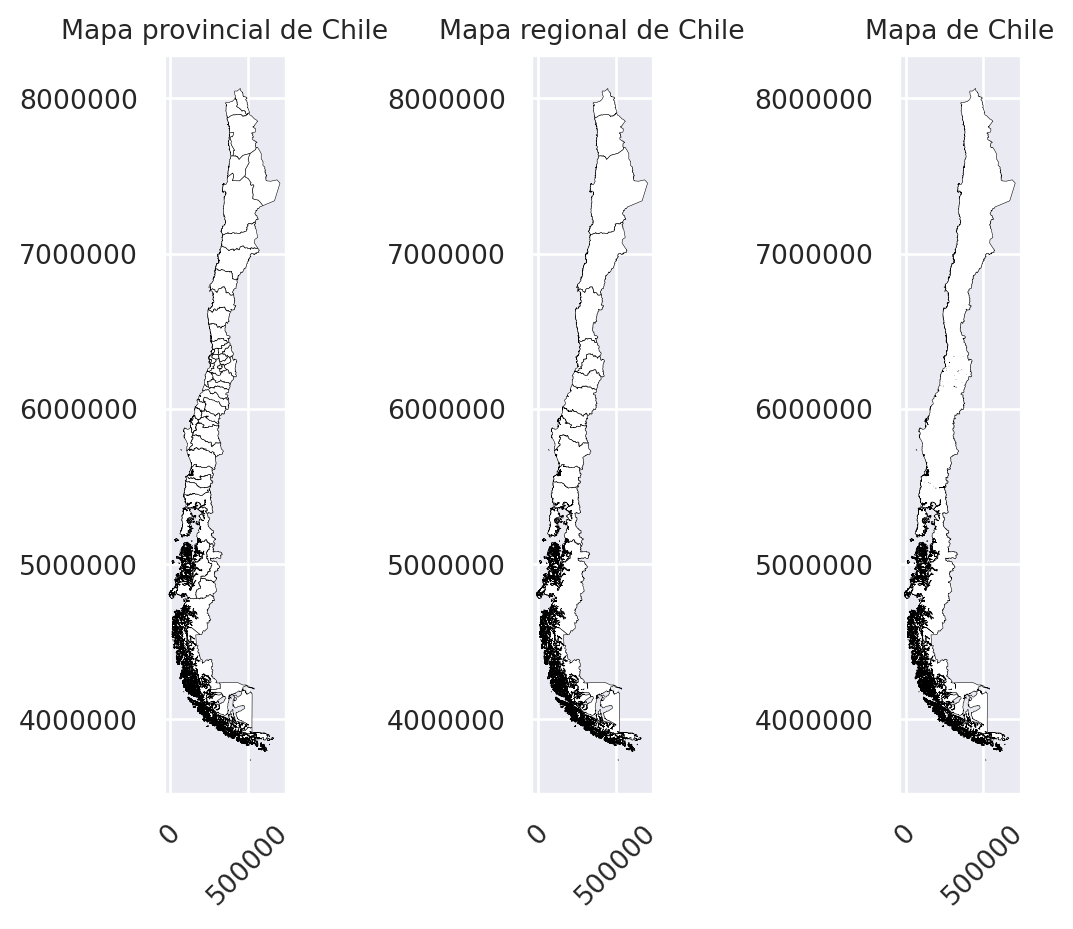
De esta forma, al plotear estos objetos, podemos ver el los distintos tipos de mapas que se obtienen con distintos parámetros del método de disolver.
fig, (ax1, ax2, ax3) = plt.subplots(nrows = 1,
ncols = 3)
provincias.plot(ax = ax1,
color = "white",
edgecolor = "black",
linewidth = 0.2)
ax1.set_title("Mapa provincial de Chile",
fontsize = 10)
ax1.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax1.tick_params(axis = "y",
labelsize = 10)
ax1.ticklabel_format(style='plain')
regiones.plot(ax = ax2,
color = "white",
edgecolor = "black",
linewidth = 0.2)
ax2.set_title("Mapa regional de Chile",
fontsize = 10)
ax2.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax2.tick_params(axis = "y",
labelsize = 10)
ax2.ticklabel_format(style='plain')
chile.plot(ax = ax3,
color = "white",
edgecolor = "black",
linewidth = 0.2)
ax3.set_title("Mapa de Chile",
fontsize = 10)
ax3.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax3.tick_params(axis = "y",
labelsize = 10)
ax3.ticklabel_format(style='plain')
plt.show()
Creación de Buffers en capas vectoriales
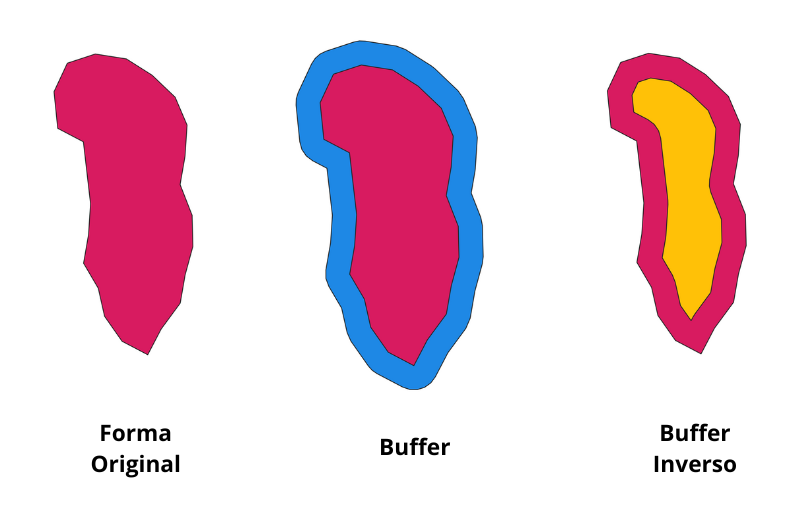
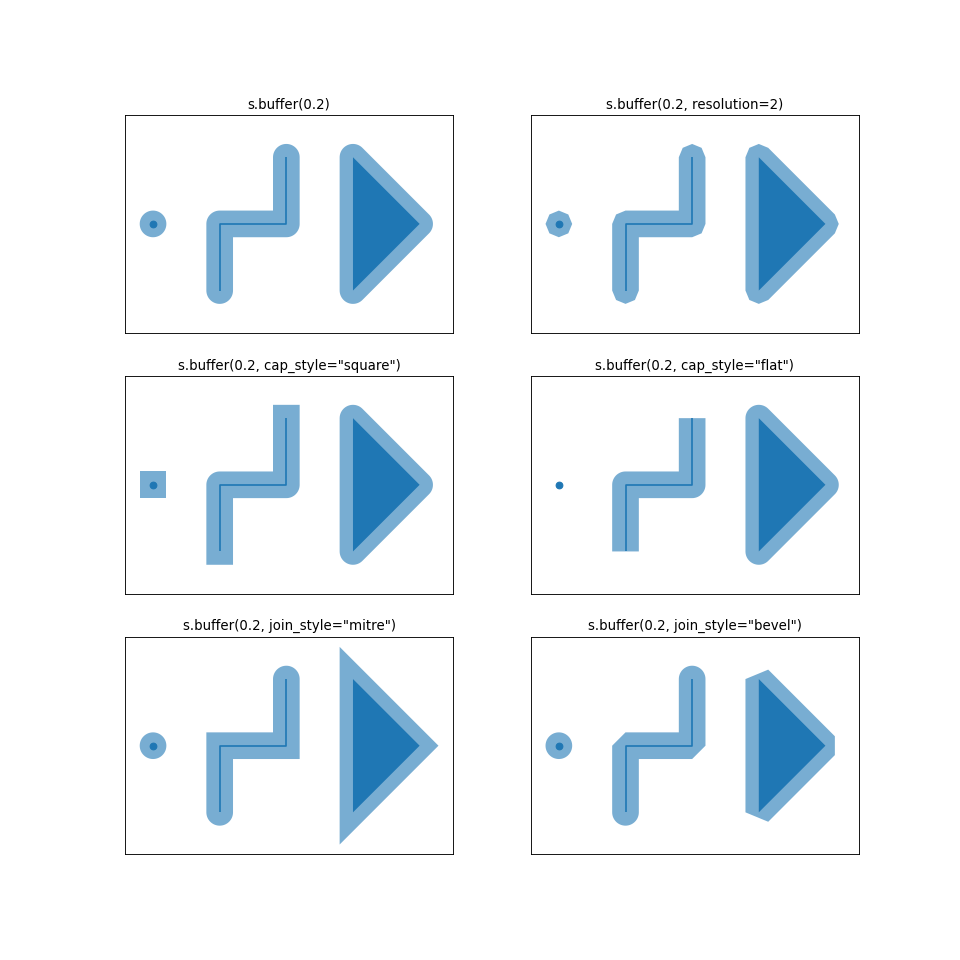
Un buffer (o zona de influencia) es un área que rodea una geometría a una distancia determinada. El área resultante se puede interpretar como la zona de influencia que una entidad o fenómeno ejerce dentro de ese rango. Por ejemplo, si se desea evaluar el riesgo de inundación asociado a un cuerpo de agua con una cota de seguridad de 10 metros, se puede crear un buffer con esa misma distancia para analizar las áreas que podrían estar en riesgo. Otro ejemplo es el alcance de las antenas de radio: al generar un buffer alrededor de la ubicación de la antena, es posible visualizar el área donde la señal de radio podría llegar con mayor intensidad, facilitando la planificación de la cobertura de transmisión. Esta área puede ser aplicada a entidades de tipo punto, línea o polígono, y en el caso de estos últimos, los buffers pueden ser creados tanto para ver la influencia externa del objeto como a la inversa, como una influencia recibida.
Dentro de GeoPandas se puede crear un buffer a través de .buffer(), teniendo como posibles parámetros:
distance =: El radio del buffer.
resolution =: Especifica cuántos segmentos lineales se utilizarán para representar un arco en un cuarto de círculo. En otras palabras, mientas tenga mas resolución, la figura se verá más circular.
Es importante mencionar que la distancia del buffer estará en las unidades de medida del CRS. En este caso, ocuparemos el AOI reproyectado, el cual está en metros.
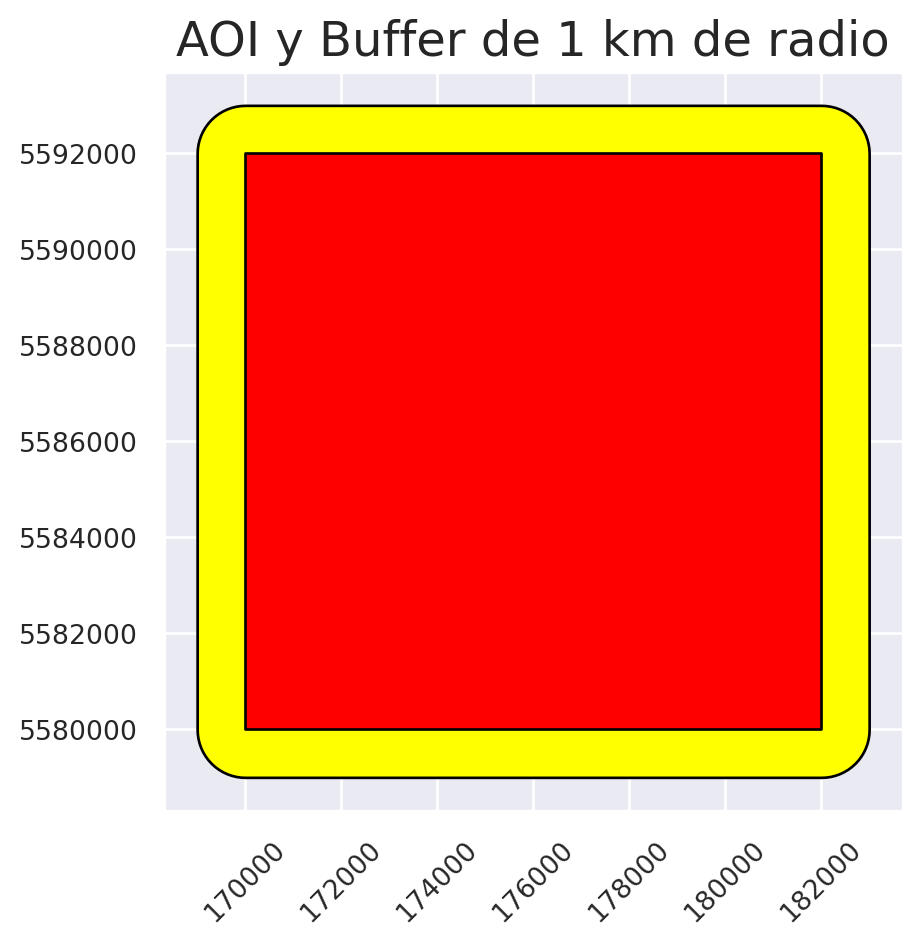
# Se crea un buffer de 1 km de radio
buffer_aoi = aoi_reproyec.buffer(distance = 1000)
Para graficar hay que tener en cuenta el orden de las capas. Primero se muestra la más grande (buffer) y después las más pequeñas (AOI).
fig, ax = plt.subplots()
buffer_aoi.plot(ax = ax,
color = 'yellow', # Especificamos el color
edgecolor = "black",
linewidth = 1)
aoi_reproyec.plot(ax = ax,
color = 'red', # Especificamos el color
edgecolor = "black",
linewidth = 1)
ax.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax.tick_params(axis = "y",
labelsize = 10)
ax.ticklabel_format(style='plain')
ax.set_title("AOI y Buffer de 1 km de radio")
plt.show()
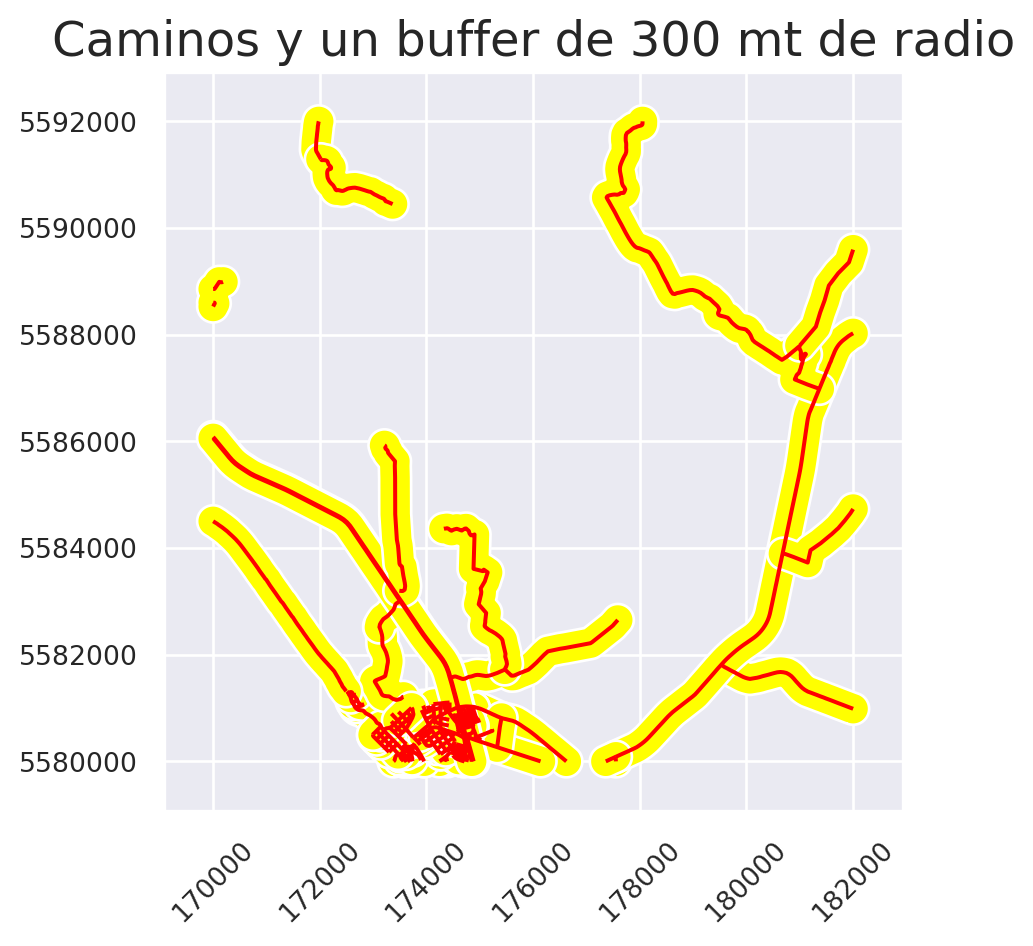
De similar manera, podemos crear buffers a otras geometrías, como por ejemplo, a los caminos (caminos_clip):
# Se crea un buffer de 300 mt de radio
buffer_caminos = caminos_clip.buffer(distance = 300)
fig, ax = plt.subplots()
buffer_caminos.plot(ax = ax,
color = "yellow")
caminos_clip.plot(ax = ax,
color = "red")
ax.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax.tick_params(axis = "y",
labelsize = 10)
ax.ticklabel_format(style='plain')
ax.set_title("Caminos y un buffer de 300 mt de radio")
plt.show()
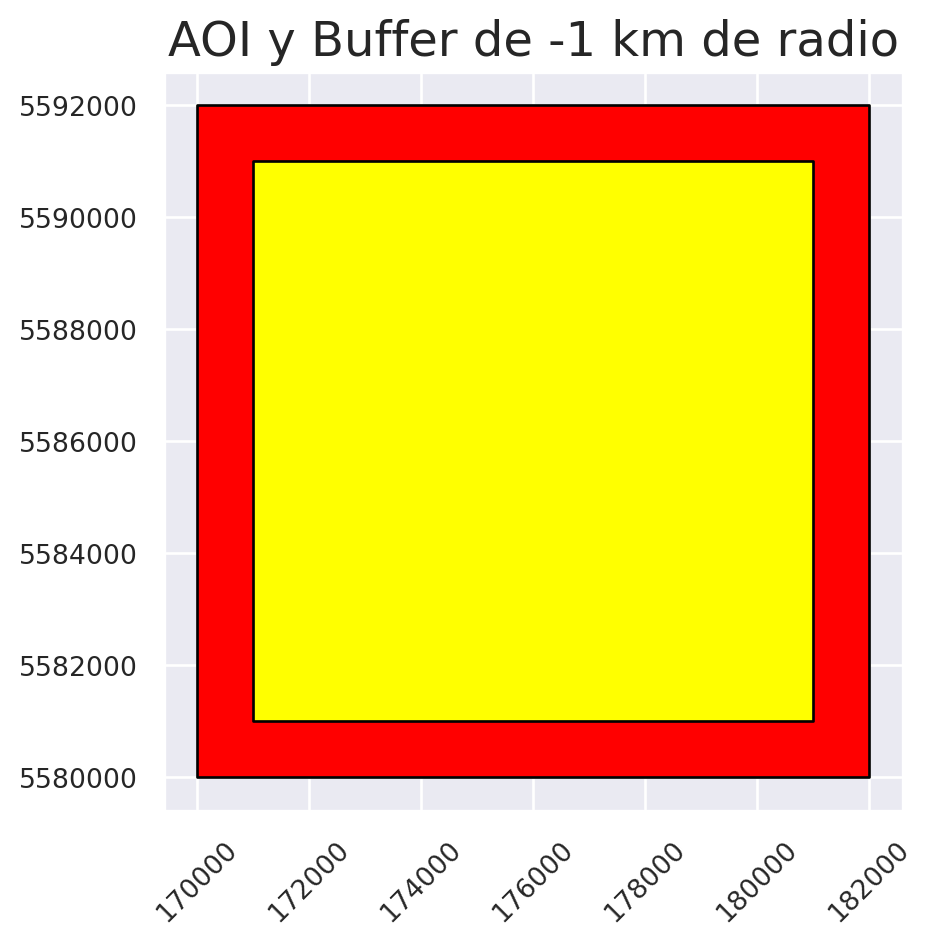
De manera parecida, se pueden crear buffers inversos, especificando un valor negativo al crearlo:
# Se crea un buffer inverso de 1 km de radio
buffer_inverso = aoi_reproyec.buffer(distance = -1000)
fig, ax = plt.subplots()
aoi_reproyec.plot(ax = ax,
color = 'red', # Especificamos el color
edgecolor = "black",
linewidth = 1)
buffer_inverso.plot(ax = ax,
color = 'yellow', # Especificamos el color
edgecolor = "black",
linewidth = 1)
ax.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax.tick_params(axis = "y",
labelsize = 10)
ax.ticklabel_format(style='plain')
ax.set_title("AOI y Buffer de -1 km de radio")
plt.show()
Hay otros parámetros que no hemos tocado que determinan la forma del buffer. Para más información, puede revisarlo en su documentación.
 {10-06}
{10-06}
Intersección entre capas vectoriales
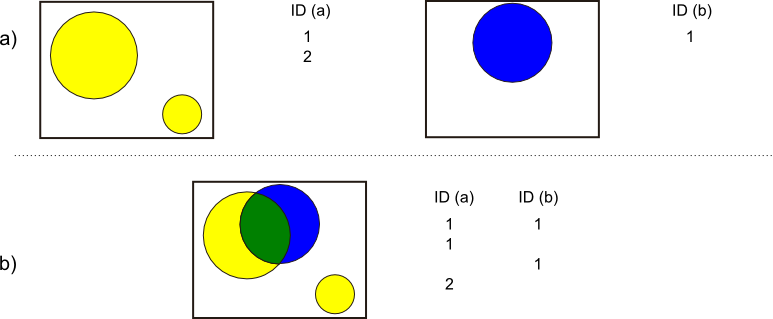
Usar la intersección es adecuado cuando se quiere identificar y extraer las áreas, líneas o puntos que son comunes a dos o más capas vectoriales. La intersección permite combinar capas geográficas para crear una nueva capa que solo contiene las geometrías y atributos de las entidades que se superponen espacialmente. Esto es especialmente útil en el análisis espacial cuando se desea obtener áreas de coincidencia, como por ejemplo, identificar las zonas donde se solapan diferentes tipos de uso de suelo con áreas protegidas o zonas de riesgo. Aplicar una intersección permite enfocarse en las áreas de interés que cumplen con múltiples criterios espaciales, optimizando el análisis y la toma de decisiones basada en datos geoespaciales.
Para hacer esto, GeoPandas ocupa el método .overlay(), el cual puede realizar distintas operaciones de sobreposición entre GeoDataFrames. Algunos de sus parámetros son :
df2 =: Otro GeoDataFrames para realizar la operación.
how =: Método espacial de sobreposición. Se puede entregar los strings: "intersection", "union", "identity", "symmetric_difference" o "difference".
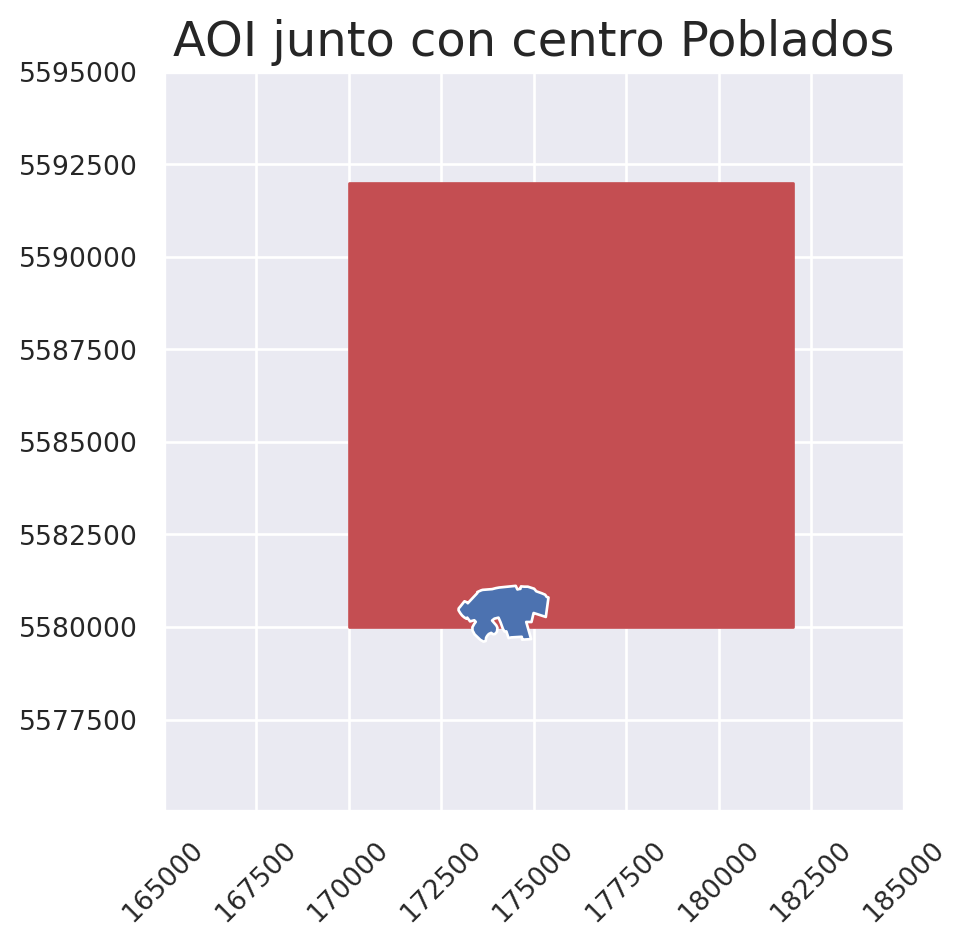
En este caso, estamos interesados en ocupar la intersection entre capas. Para visualizar esto, primero graficaremos nuestra AOI junto con los centros poblados:
fig, ax = plt.subplots()
aoi_reproyec.plot(ax = ax,
color = 'r',
edgecolor = "r",
linewidth = 1)
areas_pobladas.plot(ax = ax)
ax.set(xlim = [165000, 185000],
ylim = [5575030, 5595000])
ax.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax.tick_params(axis = "y",
labelsize = 10)
ax.ticklabel_format(style='plain')
ax.set_title("AOI junto con centro Poblados")
plt.show()
En este específico caso, nuestra AOI coincide espacialmente con Paillaco. Para calcular su intersección se vería de la siguiente forma:
interseccion_aoi = aoi_reproyec.overlay(areas_pobladas,
how = "intersection")
interseccion_aoi
| 0 |
NaN |
166 |
Los Lagos |
4.001096e+06 |
11056.044036 |
Los Lagos |
Ciudad |
POLYGON ((174150.422 5580000, 174104.141 55801... |
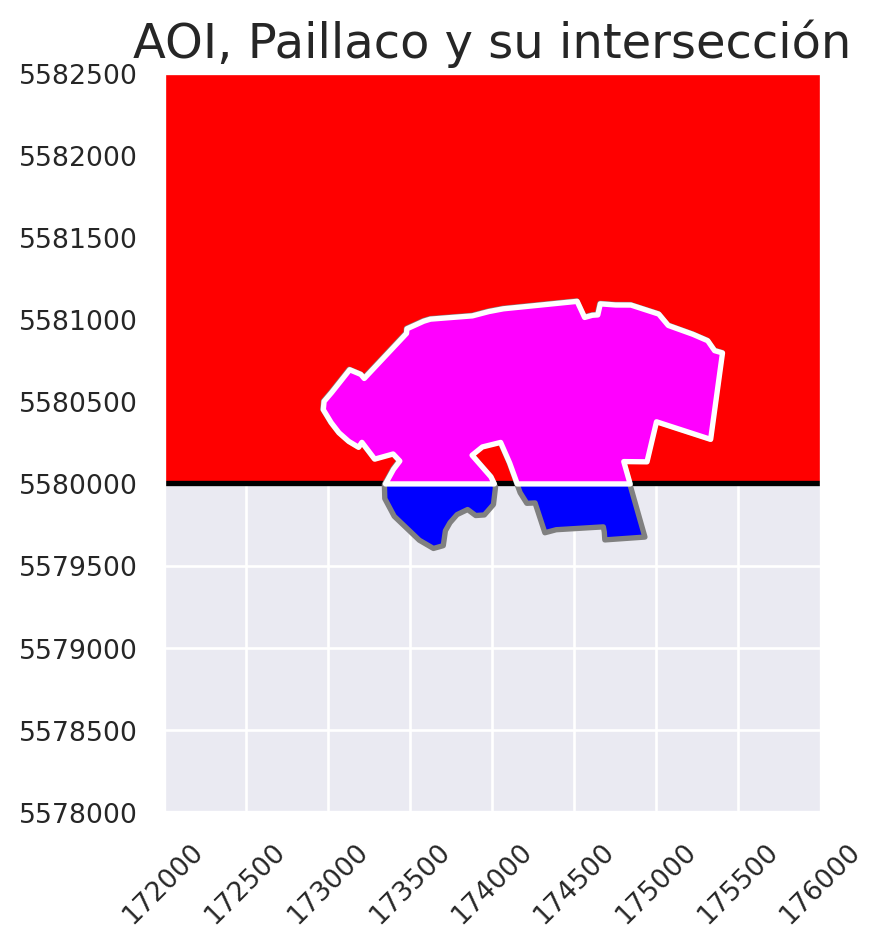
Para ver el resultado de la intersección, podemos gráficar todos las capas:
fig, ax = plt.subplots()
aoi_reproyec.plot(ax = ax,
color = 'red',
edgecolor = "black",
linewidth = 2)
areas_pobladas.plot(ax = ax,
color = "blue",
edgecolor = "grey",
linewidth = 2)
interseccion_aoi.plot(ax = ax,
color = "magenta",
linewidth = 2)
ax.set(xlim = [172000, 176000],
ylim = [5578000, 5582500])
ax.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax.tick_params(axis = "y",
labelsize = 10)
ax.ticklabel_format(style='plain')
ax.set_title("AOI, Paillaco y su intersección")
plt.show()
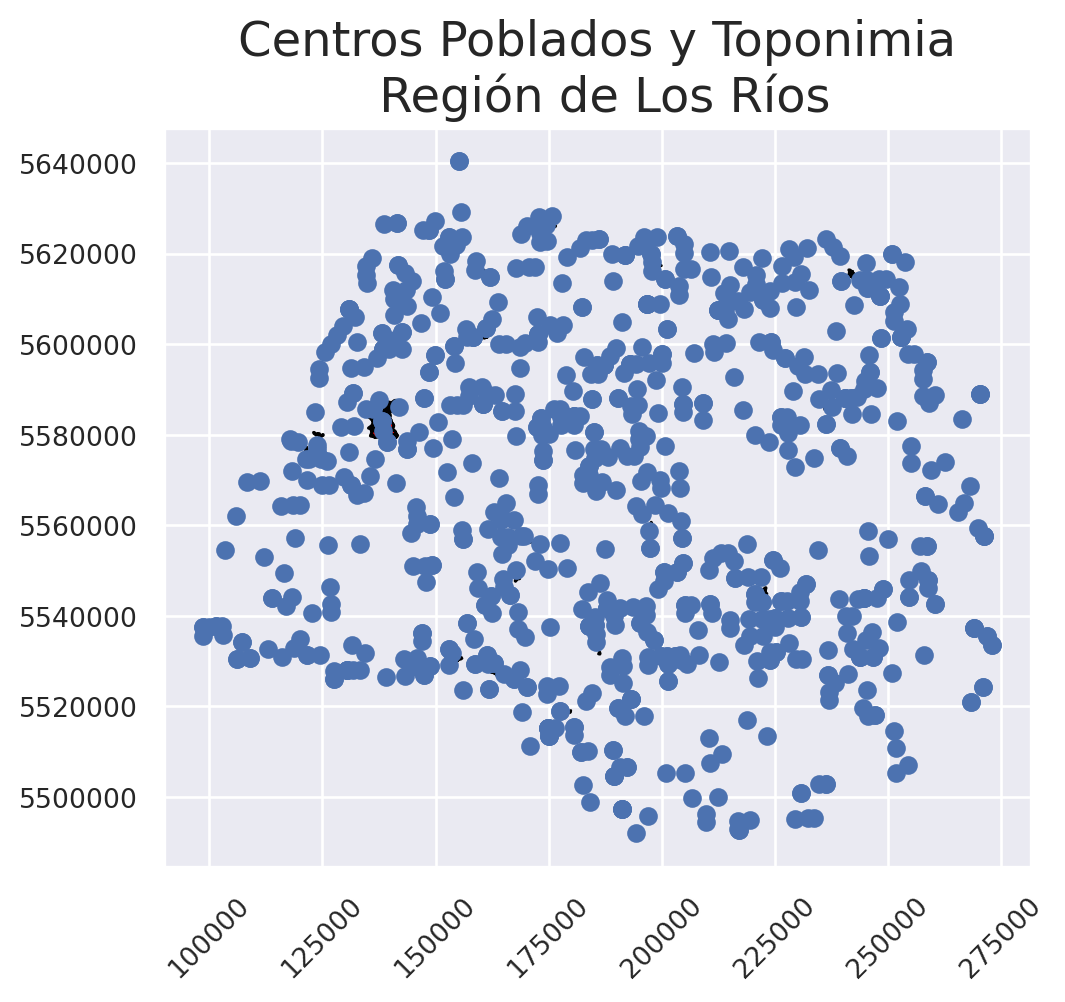
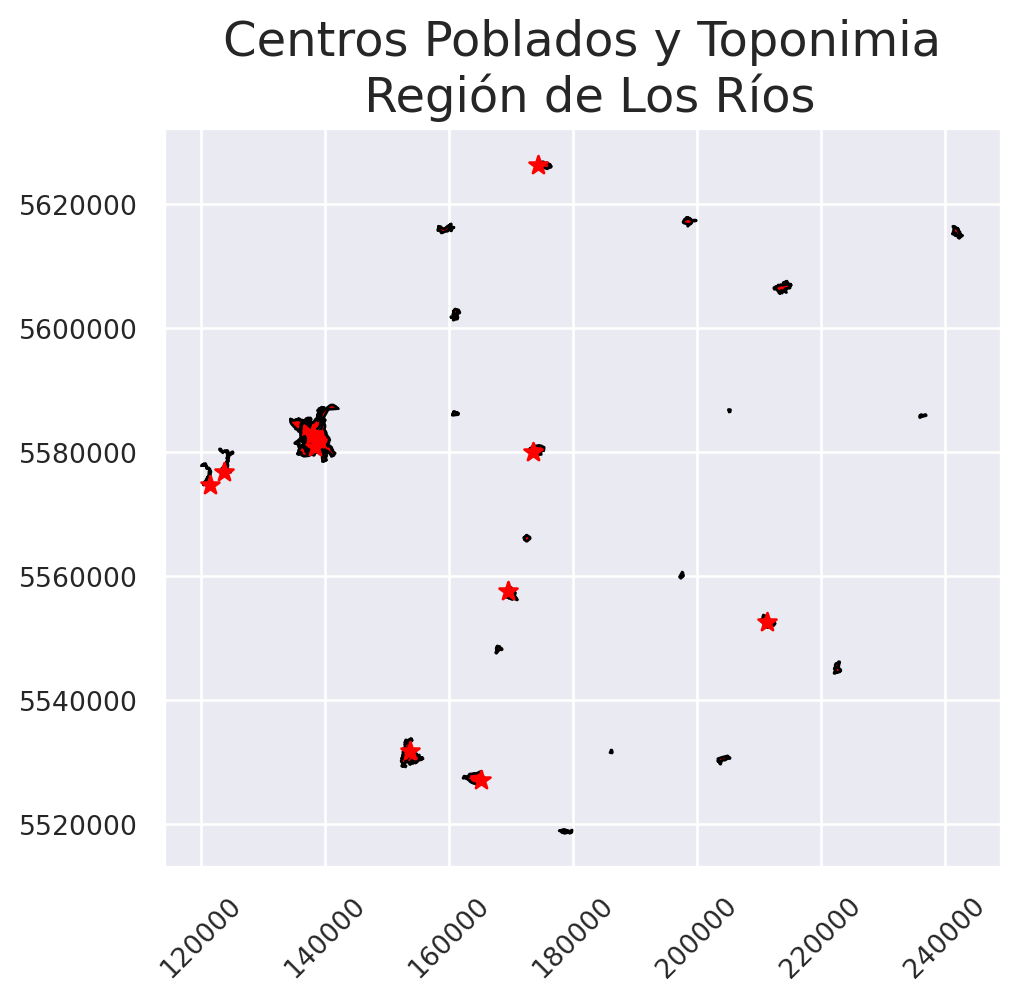
Si quisiéramos obtener la intersección entre una capa de puntos con otra de polígonos, podemos ocupar la capa de toponimia y de áreas pobladas Veamos cómo se grafican nuestros datos:
fig, ax = plt.subplots()
areas_pobladas.plot(ax = ax,
color = 'red',
edgecolor = "black",
linewidth = 1)
toponimia.plot(ax = ax)
ax.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax.tick_params(axis = "y",
labelsize = 10)
ax.ticklabel_format(style='plain')
ax.set_title("Centros Poblados y Toponimia\n Región de Los Ríos")
plt.show()
Vemos que existen muchos más cotas de toponimia de centros poblados. Esto es debido a que toponimia contempla centros poblados, comunas, elementos del relieve, infraestructuras y obras ferroviarias, localidades, redes hidrográficas y termas. En el caso de que sólo nos interese tener puntos que indiquen el nombre de las áreas pobladas, podemos calcular la intersección entre estas dos capas.
interseccion_pobladas = toponimia.overlay(areas_pobladas,
how = 'intersection')
interseccion_pobladas.head()
| 0 |
316 |
None |
14107.0 |
Paillaco |
Comuna |
PAILLACO |
VALDIVIA |
DE LOS RIOS |
179 |
Paillaco |
3.397504e+06 |
13150.476320 |
Paillaco |
Ciudad |
POINT (169519.362 5557731.909) |
| 1 |
1932 |
P |
14101.0 |
Ciudad de Valdivia |
Centro Poblado |
VALDIVIA |
VALDIVIA |
DE LOS RIOS |
167 |
Valdivia |
4.393803e+07 |
123233.022172 |
Valdivia |
Ciudad |
POINT (138101.276 5583006.678) |
| 2 |
315 |
None |
14102.0 |
Corral |
Comuna |
CORRAL |
VALDIVIA |
DE LOS RIOS |
154 |
Corral |
2.068788e+06 |
21309.635990 |
Corral |
Pueblo |
POINT (121454.61 5574767.63) |
| 3 |
314 |
None |
14101.0 |
Valdivia |
Comuna |
VALDIVIA |
VALDIVIA |
DE LOS RIOS |
167 |
Valdivia |
4.393803e+07 |
123233.022172 |
Valdivia |
Ciudad |
POINT (138445.04 5580892.789) |
| 4 |
730 |
P |
14103.0 |
Lanco |
Centro Poblado |
LANCO |
VALDIVIA |
DE LOS RIOS |
778 |
Lanco |
2.792300e+06 |
11416.032640 |
Lanco |
Aldea |
POINT (174460.718 5626439.541) |
Si ploteamos esta nueva capa de puntos, obtenemos lo siguiente:
fig, ax = plt.subplots()
areas_pobladas.plot(ax = ax,
color = 'red', # Especificamos el color
edgecolor = "black",
linewidth = 1)
interseccion_pobladas.plot(ax = ax,
marker = "*",
markersize = 50,
color = "red")
ax.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax.tick_params(axis = "y",
labelsize = 10)
ax.ticklabel_format(style='plain')
ax.set_title("Centros Poblados y Toponimia\n Región de Los Ríos")
plt.show()
Uniendo capas vectoriales
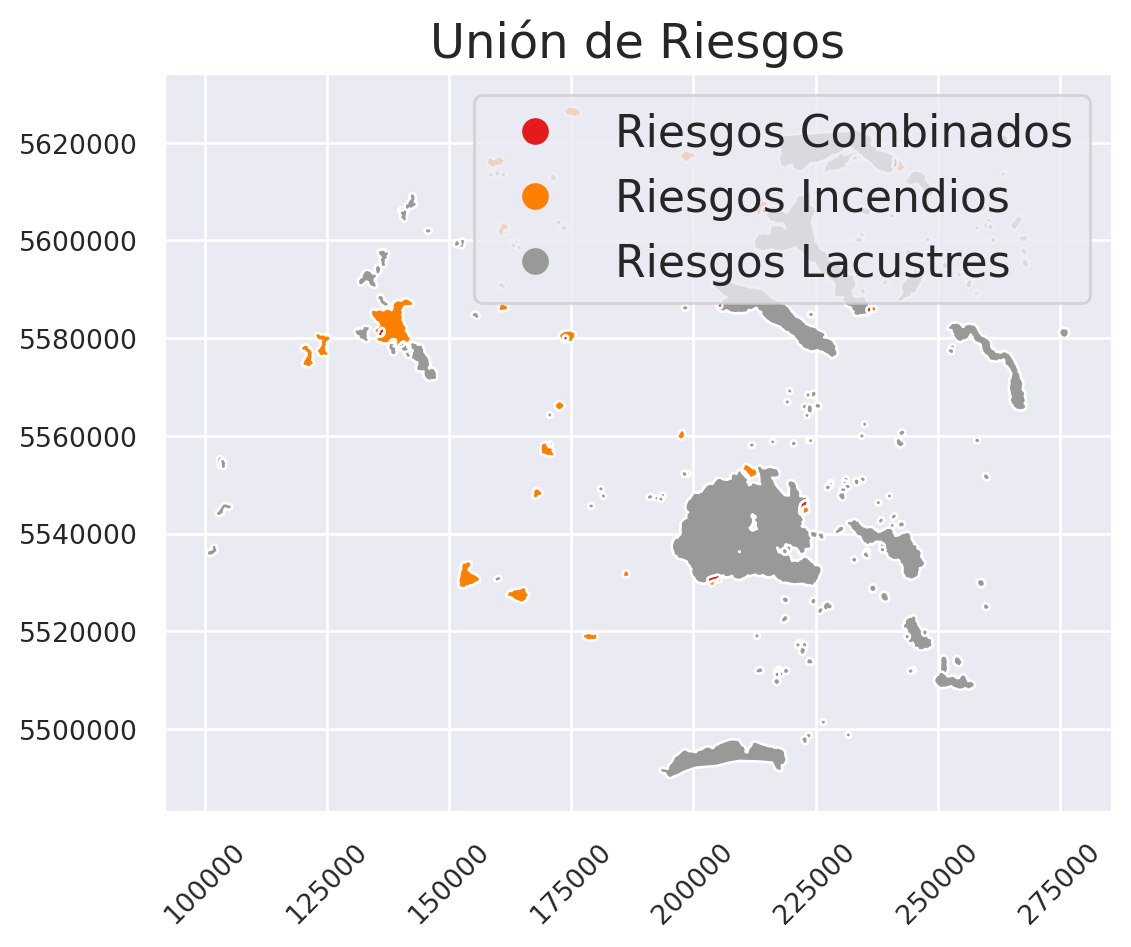
Unir datos es adecuado cuando se desea combinar dos o más capas espaciales para obtener una nueva capa que contenga todas las geometrías y atributos de ambas capas originales. A diferencia de la intersección, la unión conserva todas las geometrías, tanto las que se superponen como las que no, permitiendo realizar análisis que incluyan la totalidad del espacio cubierto por ambas capas. Esto es especialmente útil cuando se necesita analizar la relación espacial entre capas que no necesariamente se solapan completamente, como cuando se combinan capas de diferentes tipos de coberturas del suelo con datos de zonificación para obtener una capa que contenga toda la información disponible. La herramienta de unión facilita el análisis integral y la creación de nuevos conjuntos de datos con información completa y detallada para cada área o entidad geográfica.
Como ejemplo, crearemos un mapa de riesgos simplificado que considere dos fuentes: los riesgos de incendios en las cercanías de áreas urbanas y los riesgos de inundaciones cercanas a cuerpos de agua. La existencia de cualquiera de estos es problemática, pero es fundamental prestar especial atención al efecto combinado de ambos. Para este análisis, aplicaremos un buffer a las capas de cuerpos lacustres y zonas pobladas (como posibles fuentes de riesgo) y luego uniremos estos resultados para generar el mapa final de riesgos.
Esta vez, el proceso de creación de los buffers será algo distinto. En este caso, copiaremos nuestro GeoDataFrame original y dentro de este, calcularemos la zona de influencia dentro de la columna de geometría. Esto para conservar los atributos de la capa madre hacia los buffers. De manera arbitraría, calcularemos el buffer de ambos riesgos a 500 metros:
# Copiamos el mismo gdf
buffer_ciudades = areas_pobladas.copy()
# Seleccionando su geometría, calculamos el buffer dentro de la geometría del gdf original.
buffer_ciudades["geometry"] = areas_pobladas.geometry.buffer(distance = 500)
buffer_lacustres = masas_lacustres.copy()
buffer_lacustres['geometry'] = masas_lacustres.geometry.buffer(distance = 500)
Finalmente, para calcular la unión de estos, se puede seguir el mismo procedimiento de la intersección anterior cambiando el método a "union", quedando de la siguiente manera:
union_riesgos = buffer_lacustres.overlay(buffer_ciudades,
how = "union")
union_riesgos
| 0 |
14374.0 |
1.972704e+08 |
115055.657585 |
Lago Calafquen |
Lago |
158.0 |
Panguipulli |
2.145415e+06 |
11524.963127 |
Coñaripe |
Pueblo |
POLYGON ((241334.351 5616969.982, 241348.604 5... |
| 1 |
14388.0 |
1.972704e+08 |
115055.657585 |
Lago Calafquen |
Lago |
158.0 |
Panguipulli |
2.145415e+06 |
11524.963127 |
Coñaripe |
Pueblo |
POLYGON ((241334.351 5616969.982, 241348.604 5... |
| 2 |
14403.0 |
1.932754e+08 |
164375.708054 |
Lago Panguipulli |
Lago |
159.0 |
Panguipulli |
3.963212e+06 |
16946.046032 |
Panguipulli |
Ciudad |
POLYGON ((214423.754 5605323.278, 214401.771 5... |
| 3 |
14403.0 |
1.932754e+08 |
164375.708054 |
Lago Panguipulli |
Lago |
12071.0 |
Panguipulli |
3.983592e+05 |
3901.727185 |
Choshuenco |
Aldea |
POLYGON ((236229.786 5586563.369, 236230.359 5... |
| 4 |
14458.0 |
1.519835e+08 |
103413.130884 |
Lago Rinihue |
Lago |
31272.0 |
Los Lagos |
1.447750e+05 |
1828.885935 |
Los Lagos |
Pueblo |
POLYGON ((205101.695 5586072.622, 205081.169 5... |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
| 224 |
NaN |
NaN |
NaN |
NaN |
NaN |
177.0 |
Lago Ranco |
1.622894e+06 |
8447.051099 |
Lago Ranco |
Pueblo |
POLYGON ((205716.883 5531102.919, 205750.446 5... |
| 225 |
NaN |
NaN |
NaN |
NaN |
NaN |
18071.0 |
Río Bueno |
1.090913e+06 |
7918.757222 |
Crucero |
Aldea |
POLYGON ((177796.862 5518461.9, 177701.836 551... |
| 226 |
NaN |
NaN |
NaN |
NaN |
NaN |
18075.0 |
Ranco |
2.003972e+05 |
1902.487347 |
Diumén |
Aldea |
POLYGON ((185669.506 5532039.287, 185669.605 5... |
| 227 |
NaN |
NaN |
NaN |
NaN |
NaN |
180.0 |
Rio Bueno |
7.057228e+06 |
13415.355539 |
Rio Bueno |
Ciudad |
POLYGON ((162533.071 5526967.232, 162517.518 5... |
| 228 |
NaN |
NaN |
NaN |
NaN |
NaN |
176.0 |
La Unión |
1.013017e+07 |
37195.966604 |
La Unión |
Ciudad |
POLYGON ((151895.786 5530547.12, 151897.962 55... |
229 rows × 12 columns
Al imprimir la tabla de atributos de union_riesgos, se pueden observar valores NaN en las columnas que van desde objectid_1 hasta Tipo. Esto ocurre porque, al realizar la unión de ambas capas con sus atributos, se conservan los registros tanto de las capas originales como de las áreas de intersección. Los atributos del buffer_lacustres contienen únicamente sus propios atributos. Por otro lado, los atributos del buffer_ciudades se incorporan parcialmente, dependiendo de la intersección. La tabla resultante incluye los atributos combinados de ambas capas. Además, las filas donde no hay coincidencia entre los atributos presentan valores NaN en las columnas correspondientes a la capa faltante. Esto se puede explicar en el siguiente ejemplo:
 {10-09}
{10-09}
Podemos aprovechar este resultado para crear una nueva columna que identifique el origen de los datos. Si la columna objectid_1 contiene un valor NaN, el buffer pertenece a las ciudades; si la columna objectid_2 es NaN, el buffer corresponde a las masas lacustres. Si ninguna de las dos columnas contiene valores NaN, entonces el buffer representa la intersección de ambas capas.
Para realizar esta categorización, podemos crear una nueva columna en la tabla de atributos y, utilizando las filas donde hay valores NaN, asignar la categoría correspondiente en esta nueva columna. nos podemos ayudar de tres funciones:
.loc(): Nos ayuda a localizarnos en un GeoDataFrame a través de la etiquetas (como se vió en el capítulo 8).
.isnull(): identificará y retornará los elementos NaN.
~: Al anteponer este símbolo a isnull(), GeoPandas invertirá la acción, retornando los valores que no son nulos.
Dentro de Python quedaría de la siguiente manera:
# Creamos una columna "categoria" para identificar los diferentes origenes dela geometría
union_riesgos['categoria'] = None
# Buffer de ciudades (solo cuando objectid_1 es nulo)
union_riesgos.loc[union_riesgos["objectid_1"].isnull(), 'categoria'] = 'Riesgos Incendios'
# Buffer cuerpos lacustres (solo cuando objectid_2 es nulo)
union_riesgos.loc[union_riesgos["objectid_2"].isnull(), 'categoria'] = 'Riesgos Lacustres'
# Intersección de ambos (ninguno es nulo)
union_riesgos.loc[~ (union_riesgos["objectid_1"].isnull()) & ~ (union_riesgos["objectid_2"].isnull()), 'categoria'] = 'Riesgos Combinados'
Al tener etiquetado el origen de los buffers podemos graficarlos para entenderlos mejor:
fig, ax = plt.subplots()
# Graficar usando la columna "categoria" con legend=True
union_riesgos.plot(column = 'categoria',
ax = ax,
legend = True,
cmap = 'Set1')
ax.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax.tick_params(axis = "y",
labelsize = 10)
# Añadir título
plt.title('Unión de Riesgos')
ax.ticklabel_format(style='plain')
# Mostrar el gráfico
plt.show()
Fusionando (Merge) datos vectoriales
Fusionar (o Merge en inglés) es una herramienta que combina múltiples capas o datasets de la misma clase geométrica (puntos, líneas o polígonos) en una sola capa. A pesar de sus similitudes con la Unión, estos combinan datos de maneras distintas y con diferentes propósitos.
Mientras que la unión combina tanto la geometría como los atributos de las capas originales, resultando en nuevas entidades con los atributos de ambos conjuntos de datos, Merge no tiene en cuenta las relaciones espaciales entre las entidades, sino que simplemente agrega todos los elementos de varias capas en una única capa sin modificar las geometrías. Por ejemplo, si se tienen varias capas de diferentes áreas geográficas, se pueden “fusionar” en una sola capa que contenga todas las entidades. Merge es útil cuando se necesita unir datos sin hacer análisis espacial, simplemente combinando múltiples conjuntos de datos de manera directa.
Para hacer esta fusión, podemos ayudarnos del método concat de Pandas, indicando en una lista los elementos que queramos unir:
merge = gpd.GeoDataFrame(pd.concat([areas_pobladas, masas_lacustres],
ignore_index=True))
Como el resultado de pd.concat retorna un DataFrame, antes se declara la creación de un GeoDataFrame (a través de gpd.GeoDataFrame =). Para ver esta unión, podemos contar la cantidad de elementos que tienen las capas originales y la resultante:
print(f"La cantidad del objeto fusionado es de {len(merge)}\n"
f"La cantidad de áreas pobladas es de {len(areas_pobladas)}\n"
f"La cantidad de masas lacustres es de {len(masas_lacustres)}\n")
La cantidad del objeto fusionado es de 216
La cantidad de áreas pobladas es de 24
La cantidad de masas lacustres es de 192
Personalizando gráficos de Matplotlib
Ya hemos ploteado algunos resultados de los procesos, sin embargo, si se desea personalizar más los gráficos, se debe explorar las diversas opciones que Matplotlib junto con GeoPandas ofrecen. Como objetivo, construiremos una figura de la región de los Ríos que contenga los tipos de caminos, los principales centros urbanos (con etiquetas de las ciudades) y las áreas lacustres.
Para desarrollar este ejercicio, primero tenemos que generar nuestro set de datos. Deberemos filtrar la capa regiones para que obtener la región de Los Ríos y con esto, cortar caminos.
Para saber la información que contiene el objeto regiones, podemos aplicar la función .info():
<class 'geopandas.geodataframe.GeoDataFrame'>
Index: 16 entries, 1 to 9
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 geometry 16 non-null geometry
1 PROVINCIA 16 non-null object
2 NOM_REGION 16 non-null object
3 NOM_PROVIN 16 non-null object
4 TOTAL_VIVI 16 non-null int64
5 PARTICULAR 16 non-null int64
6 COLECTIVAS 16 non-null int64
7 TOTAL_PERS 16 non-null int64
8 HOMBRES 16 non-null int64
9 MUJERES 16 non-null int64
10 DENSIDAD 16 non-null float64
11 INDICE_MAS 16 non-null float64
12 INDICE_DEP 16 non-null float64
13 IND_DEP_JU 16 non-null float64
14 IND_DEP_AD 16 non-null float64
15 SHAPE_Leng 16 non-null float64
16 SHAPE_Area 16 non-null float64
dtypes: float64(7), geometry(1), int64(6), object(3)
memory usage: 2.8+ KB
Dentro de este set de datos, tenemos la columna NOM_REGION. Revisemos sus datos únicos (con .unique()):
regiones["NOM_REGION"].unique()
array(['REGIÓN DE TARAPACÁ', 'REGIÓN DE LOS LAGOS',
'REGIÓN DE AYSÉN DEL GENERAL CARLOS IBÁÑEZ DEL CAMPO',
'REGIÓN DE MAGALLANES Y DE LA ANTÁRTICA CHILENA',
'REGIÓN METROPOLITANA DE SANTIAGO', 'REGIÓN DE LOS RÍOS',
'REGIÓN DE ARICA Y PARINACOTA', 'REGIÓN DEL ÑUBLE',
'REGIÓN DE ANTOFAGASTA', 'REGIÓN DE ATACAMA', 'REGIÓN DE COQUIMBO',
'REGIÓN DE VALPARAÍSO',
"REGIÓN DEL LIBERTADOR GENERAL BERNARDO O'HIGGINS",
'REGIÓN DEL MAULE', 'REGIÓN DEL BIOBÍO', 'REGIÓN DE LA ARAUCANÍA'],
dtype=object)
Con estos datos, podemos filtrar regiones para obtener la región de Los Ríos:
los_rios = regiones[regiones["NOM_REGION"] == "REGIÓN DE LOS RÍOS"]
los_rios
| REGION |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 14 |
MULTIPOLYGON (((100232.544 5563345.025, 100268... |
141 |
REGIÓN DE LOS RÍOS |
VALDIVIA |
113694 |
113308 |
386 |
290868 |
142329 |
148539 |
28.810222 |
95.81928 |
46.959439 |
29.233443 |
17.725996 |
1.787878e+06 |
1.708160e+10 |
Una vez obtenida la región, podemos cortar la capa caminos para obtener todos los caminos de la región:
caminos_lr = caminos.clip(los_rios)
caminos_lr
| 29091 |
None |
T-985 |
3 |
Pavimento |
Rural |
14 |
16847.809 |
LINESTRING (194313.081 5492490.144, 194318.422... |
| 28898 |
None |
T-978 |
3 |
Ripio |
Rural |
14 |
8060.129 |
LINESTRING (203305.541 5500102.553, 203340.143... |
| 28989 |
None |
T-865 |
3 |
Tierra |
Rural |
14 |
3866.865 |
LINESTRING (203704.468 5524896.093, 203708.763... |
| 29019 |
None |
T-869 |
3 |
Ripio |
Rural |
14 |
10735.301 |
LINESTRING (204713.658 5530668.212, 204720.204... |
| 29029 |
None |
T-833 |
3 |
Ripio |
Rural |
14 |
3979.723 |
LINESTRING (203824.495 5530290.779, 203824.94 ... |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
| 23919 |
None |
None |
9 |
None |
Urbano |
14 |
20.093 |
LINESTRING (139710.434 5586014.941, 139730.033... |
| 23928 |
None |
None |
9 |
None |
Urbano |
14 |
42.310 |
LINESTRING (139694.8 5586071.429, 139679.274 5... |
| 23843 |
None |
None |
9 |
None |
Urbano |
14 |
905.614 |
MULTILINESTRING ((140191.94 5586471.529, 14016... |
| 23524 |
None |
S/R |
3 |
None |
Rural |
14 |
2809.090 |
LINESTRING (141028.805 5588584.928, 141022.941... |
| 16951 |
Carretera Panamericana |
Ruta 5 |
1 |
None |
Rural |
9 |
210594.625 |
LINESTRING (176368.582 5628100.035, 176367.003... |
7813 rows × 8 columns
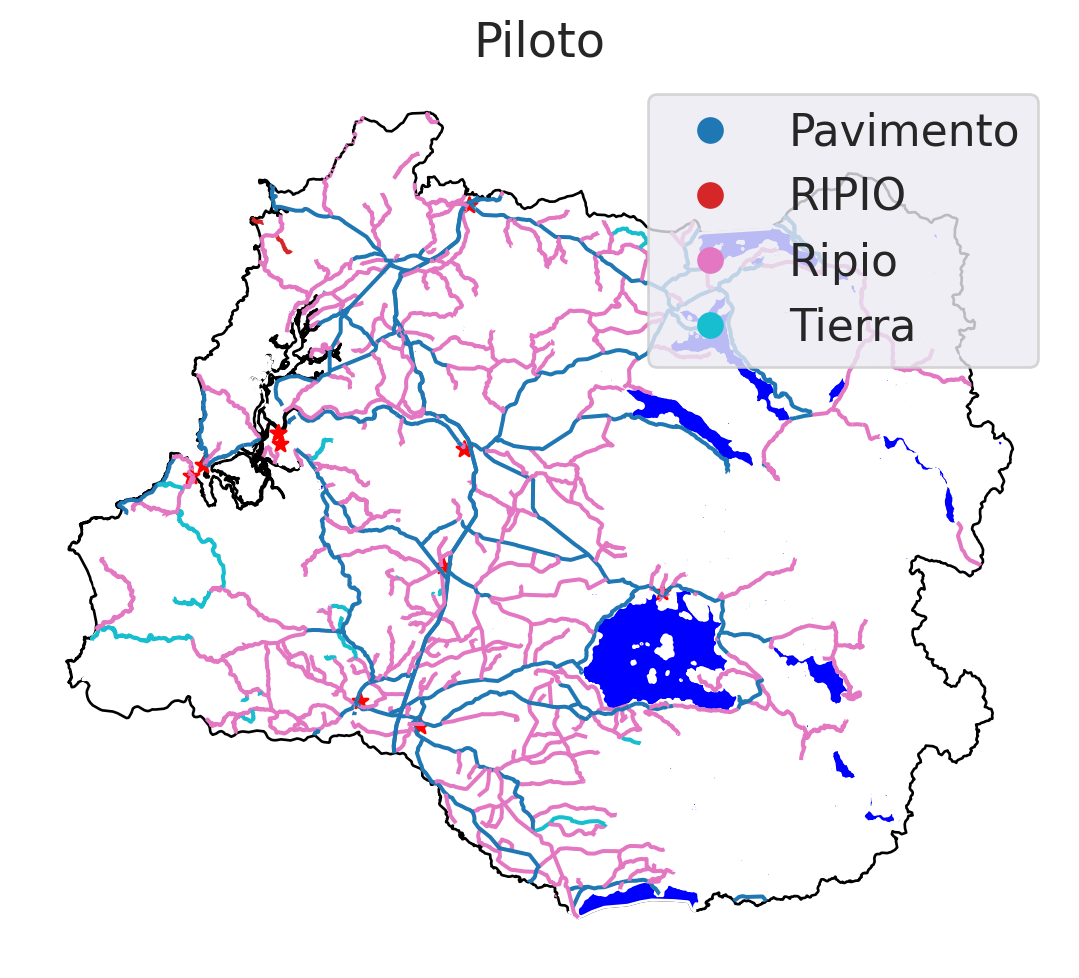
Ahora que tenemos los datos, realicemos un plot piloto:
fig, ax = plt.subplots(figsize = (10, 6))
los_rios.plot(ax = ax,
color = "white",
edgecolor='black')
masas_lacustres.plot(ax = ax,
color = "blue")
interseccion_pobladas.plot(ax = ax,
marker = "*",
color = "red")
caminos_lr.plot(ax = ax,
legend = True,
column = "Tipo_Carpe")
ax.set_axis_off()
plt.title("Piloto")
plt.show()
Durante el capítulo hemos ocupado algunos parámetros de Matplotlib para mejorar la visualización de las figuras:
ax.tick_params: Controla parámetros de las marcas de los ejes. Para esto, se debe seleccionar el axis a alterar y los cambios. En nuestro caso, cambiamos el tamaño del texto (con labelsize) y dentro del eje x, rotamos el ángulo a 45° (con labelrotation).
ax.set_axis_off(): Desactiva ambos ejes.
plot(legend=True, column="Tipo_Carpe"): Estos parámetros permiten diferenciar los objetos dentro de un mismo conjunto de datos, basándose en la columna especificada para la distinción. Para mostrar esta diferenciación en el gráfico, es necesario activar la opción de leyenda configurándola en True.
Sin embargo, no hemos cumplido con lo solicitado. Las ciudades no se presentan como etiquetas (sino como estrellas) y los caminos no están correctamente representados (ya que tiene un código de color arbitrario). Para solucionar estos problemas podemos aplicar loops y diccionarios. Además, la leyenda cubre parte del gráfico.
Representando los tipos de caminos
En el caso de querer representar nuestros caminos como líneas dentro de la leyenda, tendremos que aplicar un loop que le especifique a Matplotlib los tipos de caminos existentes. Para verificar los tipos de caminos, debemos obtener algún atributo de caminos_lr que identifique esto:
<class 'geopandas.geodataframe.GeoDataFrame'>
Index: 7813 entries, 29091 to 16951
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Nom_Ruta 5313 non-null object
1 Rol_Mop 675 non-null object
2 Clase_Ruta 7813 non-null int32
3 Tipo_Carpe 470 non-null object
4 Catego 7809 non-null object
5 Cod_Region 7813 non-null int32
6 long_mt 7813 non-null float64
7 geometry 7813 non-null geometry
dtypes: float64(1), geometry(1), int32(2), object(4)
memory usage: 488.3+ KB
Dentro de sus atributos, "Tipo_Carpe" diferencia a los caminos por el material de su superficie. Revisemos sus datos únicos:
caminos_lr["Tipo_Carpe"].unique()
array(['Pavimento', 'Ripio', 'Tierra', None, 'RIPIO'], dtype=object)
Note que la clase “Ripio” aparece con dos clasificaciones (Ripio y RIPIO). Esto se debe a un error tipográfico en la base de datos. Ignoraremos este problema por ahora. Con estos datos podemos crear una clasificación de los caminos. Si el camino es de pavimento, debe representarse en color negro y con un grosor más ancho. Para los caminos de ripio, se debe usar un color gris con un grosor reducido. Finalmente, si el camino es de tierra, debe ser café y tener un grosor aún menor. En el caso de caminos sin clasificación (None), no deben ser graficados. Estas asignaciones se gestionan fácilmente mediante estructuras clave-valor, que en Python se implementan como diccionarios. Creamos dos diccionarios para realizar esta clasificación:
caminos_colores = {"Pavimento": "black", # Negro para pavimento
"Ripio": "gray", # Gris para ripio
"Tierra": "peru", # Café para tierra
"RIPIO": "gray", # Gris para la variante de Ripio con mayúsculas
None: None} # No graficar si el valor es None
De la misma forma, creamos un diccionario para los grosores:
caminos_grosor = {"Pavimento": 2, # Grosor más grueso para pavimento
"Ripio": 1, # Grosor medio para ripio
"Tierra": 0.5, # Grosor menor para tierra
"RIPIO": 1, # Mismo grosor para la variante de Ripio con mayúsculas
None: None} # No graficar si el valor es None
Con ambos diccionarios listos, podemos volver a graficar implementándolos mediante un bucle for:
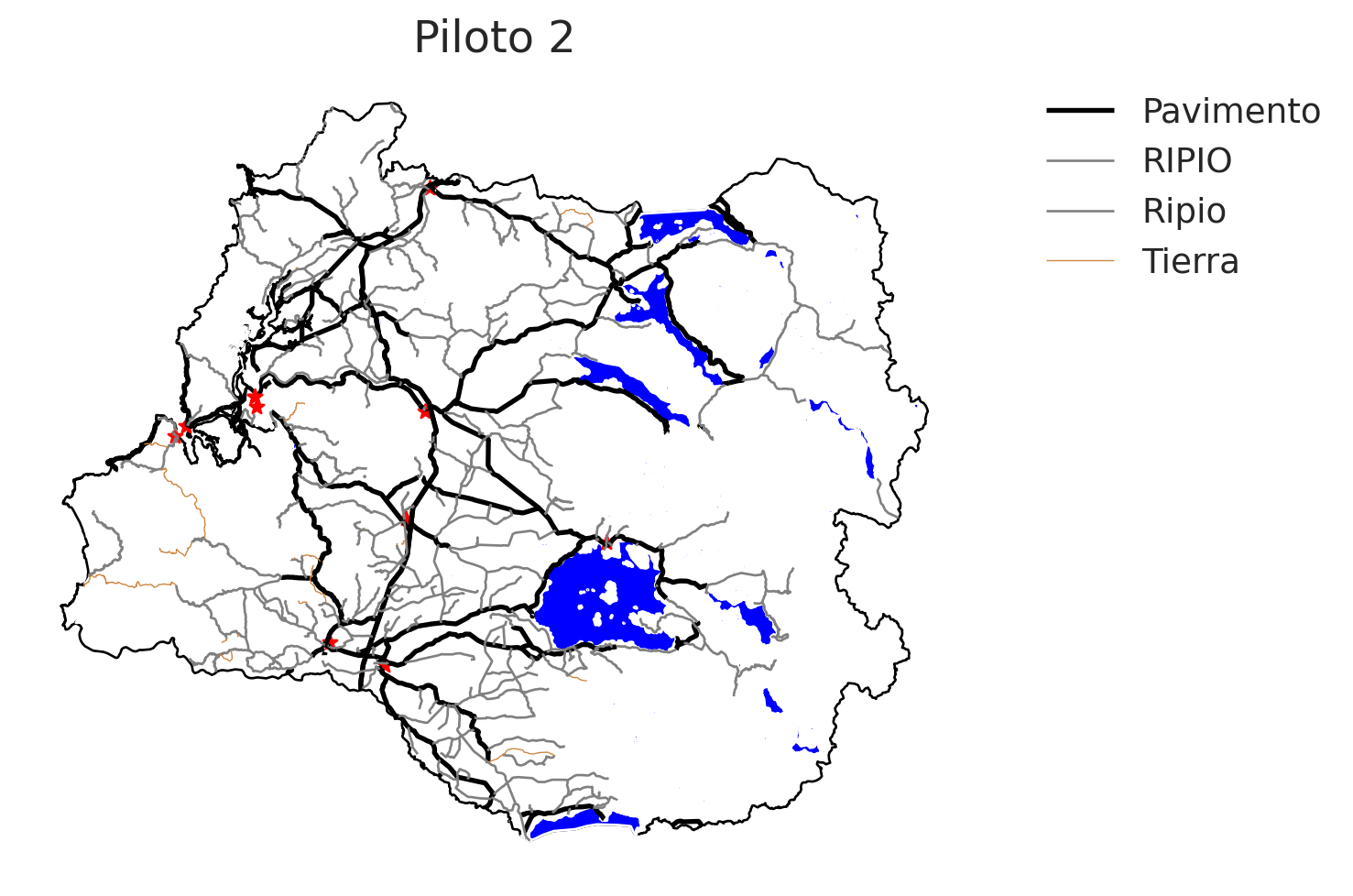
fig, ax = plt.subplots(figsize = (10, 6))
los_rios.plot(ax = ax,
color = "white",
edgecolor='black')
masas_lacustres.plot(ax = ax,
color = "blue")
interseccion_pobladas.plot(ax = ax,
marker = "*",
color = "red")
# Caminos ======
for tipo_caminos, data in caminos_lr.groupby("Tipo_Carpe"):
color = caminos_colores[tipo_caminos]
label = tipo_caminos
data.plot(color = color,
ax = ax,
linewidth = caminos_grosor[tipo_caminos],
label = label)
# Termino caminos ======
ax.set_axis_off()
# Leyenda
ax.legend(fontsize = 14,
frameon = False,
bbox_to_anchor=(1.4, 1))
plt.title("Piloto 2")
plt.show()
Desglosemos el código:
- Al graficar los caminos, se crean dos variables:
tipo_caminos y data. Estas variables se definen utilizando el método caminos_lr.groupby("Tipo_Carpe"). Este método agrupa los datos del dataset original (caminos_lr) según un atributo común, en este caso, el tipo de camino. De esta manera, el bucle for filtra la capa de caminos por cada tipo de camino, realiza una operación sobre ese grupo y repite el proceso hasta recorrer todos los grupos.
- Por ejemplo, en la primera iteración, el dataset
caminos_lr se reduce a aquellos caminos que son de pavimento. Aquí, la variable tipo_caminos toma el valor del string "Pavimento", mientras que data contiene todos los elementos que pertenecen a esa categoría.
- Luego, se obtiene el color correspondiente al pavimento accediendo al diccionario
caminos_colores, donde la clave es tipo_caminos (en este caso, “Pavimento”). Del mismo modo, se obtiene el grosor a través del diccionario caminos_grosor. Una vez que se tienen ambos valores, el código grafica únicamente los caminos pavimentados (almacenados en data), aplicando el color, grosor y su etiqueta (label) previamente asignados mediante los parámetros color y linewidth.
- Dentro de
ax.legend() se establecen parámetros para configurar la visualización de la leyenda.
fontsize regula su tamaño.frameon = False quita el marco y fondo de la leyenda.bbox_to_anchor=(1.4, 1) regula la posición de esta en la figura.
Representando etiquetas
De la misma forma que hicimos con caminos, debemos buscar un atributo de interseccion_pobladas que filtre por centros poblados:
interseccion_pobladas.head()
| 0 |
316 |
None |
14107.0 |
Paillaco |
Comuna |
PAILLACO |
VALDIVIA |
DE LOS RIOS |
179 |
Paillaco |
3.397504e+06 |
13150.476320 |
Paillaco |
Ciudad |
POINT (169519.362 5557731.909) |
| 1 |
1932 |
P |
14101.0 |
Ciudad de Valdivia |
Centro Poblado |
VALDIVIA |
VALDIVIA |
DE LOS RIOS |
167 |
Valdivia |
4.393803e+07 |
123233.022172 |
Valdivia |
Ciudad |
POINT (138101.276 5583006.678) |
| 2 |
315 |
None |
14102.0 |
Corral |
Comuna |
CORRAL |
VALDIVIA |
DE LOS RIOS |
154 |
Corral |
2.068788e+06 |
21309.635990 |
Corral |
Pueblo |
POINT (121454.61 5574767.63) |
| 3 |
314 |
None |
14101.0 |
Valdivia |
Comuna |
VALDIVIA |
VALDIVIA |
DE LOS RIOS |
167 |
Valdivia |
4.393803e+07 |
123233.022172 |
Valdivia |
Ciudad |
POINT (138445.04 5580892.789) |
| 4 |
730 |
P |
14103.0 |
Lanco |
Centro Poblado |
LANCO |
VALDIVIA |
DE LOS RIOS |
778 |
Lanco |
2.792300e+06 |
11416.032640 |
Lanco |
Aldea |
POINT (174460.718 5626439.541) |
En este caso note que Clase_Topo puede servir para obtener los centros poblados. Podemos actualizar interseccion_pobladas con un filtro de las ciudades:
interseccion_pobladas = interseccion_pobladas[interseccion_pobladas["Clase_Topo"] == "Centro Poblado"]
interseccion_pobladas
| 1 |
1932 |
P |
14101.0 |
Ciudad de Valdivia |
Centro Poblado |
VALDIVIA |
VALDIVIA |
DE LOS RIOS |
167 |
Valdivia |
4.393803e+07 |
123233.022172 |
Valdivia |
Ciudad |
POINT (138101.276 5583006.678) |
| 4 |
730 |
P |
14103.0 |
Lanco |
Centro Poblado |
LANCO |
VALDIVIA |
DE LOS RIOS |
778 |
Lanco |
2.792300e+06 |
11416.032640 |
Lanco |
Aldea |
POINT (174460.718 5626439.541) |
| 5 |
3502 |
P |
14101.0 |
Valdivia |
Centro Poblado |
VALDIVIA |
VALDIVIA |
DE LOS RIOS |
167 |
Valdivia |
4.393803e+07 |
123233.022172 |
Valdivia |
Ciudad |
POINT (138101.276 5583006.678) |
| 6 |
3694 |
P |
14202.0 |
Futrono |
Centro Poblado |
FUTRONO |
RANCO |
DE LOS RIOS |
178 |
Futrono |
3.454574e+06 |
12683.736946 |
Futrono |
Pueblo |
POINT (211279.285 5552724.286) |
Note que Valdivia aparece dos veces. Al igual que el caso anterior, se debe a un error tipográfico de la base de datos. Sin contar con esto, integremos las ciudades al gráfico a través de un bucle for:
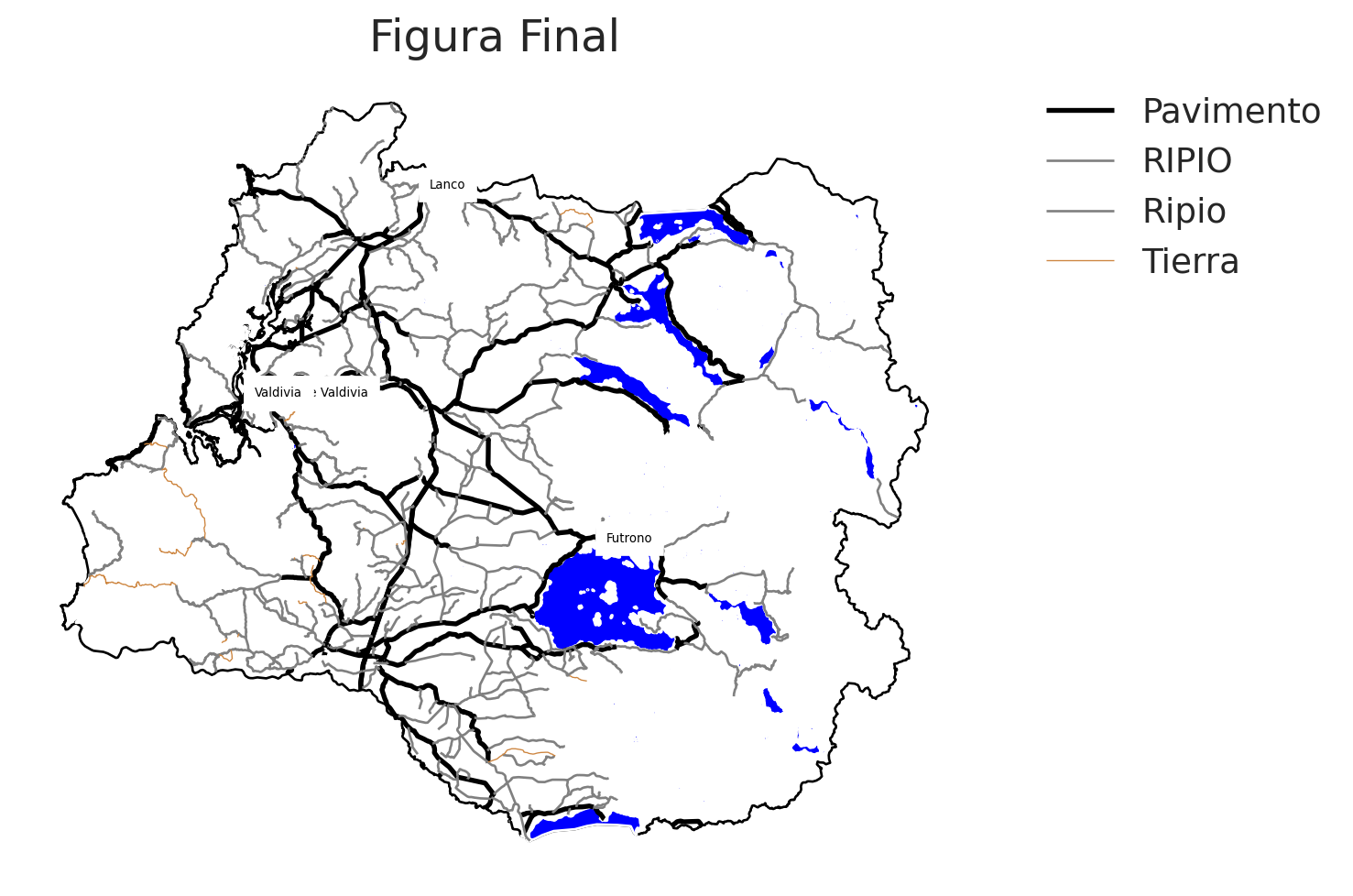
fig, ax = plt.subplots(figsize = (10, 6))
los_rios.plot(ax = ax,
color = "white",
edgecolor='black')
masas_lacustres.plot(ax = ax,
color = "blue")
interseccion_pobladas.plot(ax = ax,
marker = "*",
color = "red")
for tipo_caminos, data in caminos_lr.groupby("Tipo_Carpe"):
color = caminos_colores[tipo_caminos]
label = tipo_caminos
data.plot(color = color,
ax = ax,
linewidth = caminos_grosor[tipo_caminos],
label = label)
# Ciudades =========
for x, y, label in zip(interseccion_pobladas.geometry.x,
interseccion_pobladas.geometry.y,
interseccion_pobladas['Nombre']):
ax.text(x,
y,
label,
fontsize = 5,
color = 'black',
backgroundcolor = "white")
# Fin Ciudades =========
ax.set_axis_off()
ax.legend(fontsize = 14,
frameon = False,
bbox_to_anchor=(1.4, 1))
plt.title("Figura Final")
plt.show()
Desglose del código:
- Dentro del bucle
for, se declaran tres variables: x, y y label. Estas se definen mediante el uso de zip, que agrupa objetos iterables manteniendo el orden de sus elementos. El bucle itera sobre todos los elementos en interseccion_pobladas, extrayendo:
- La coordenada
x, que corresponde a la longitud en la geometría del objeto (interseccion_pobladas.geometry.x).
- La coordenada
y, que corresponde a la latitud en la geometría.
- El nombre del elemento, que se utiliza como etiqueta (
label).
- Una vez obtenidos estos valores, el código añade una etiqueta de texto al mapa usando
ax.text(), posicionándola en las coordenadas x e y del elemento correspondiente. Además, se definen atributos visuales como el color del texto, el color de fondo y el tamaño de la fuente.
Gráficos para publicaciones
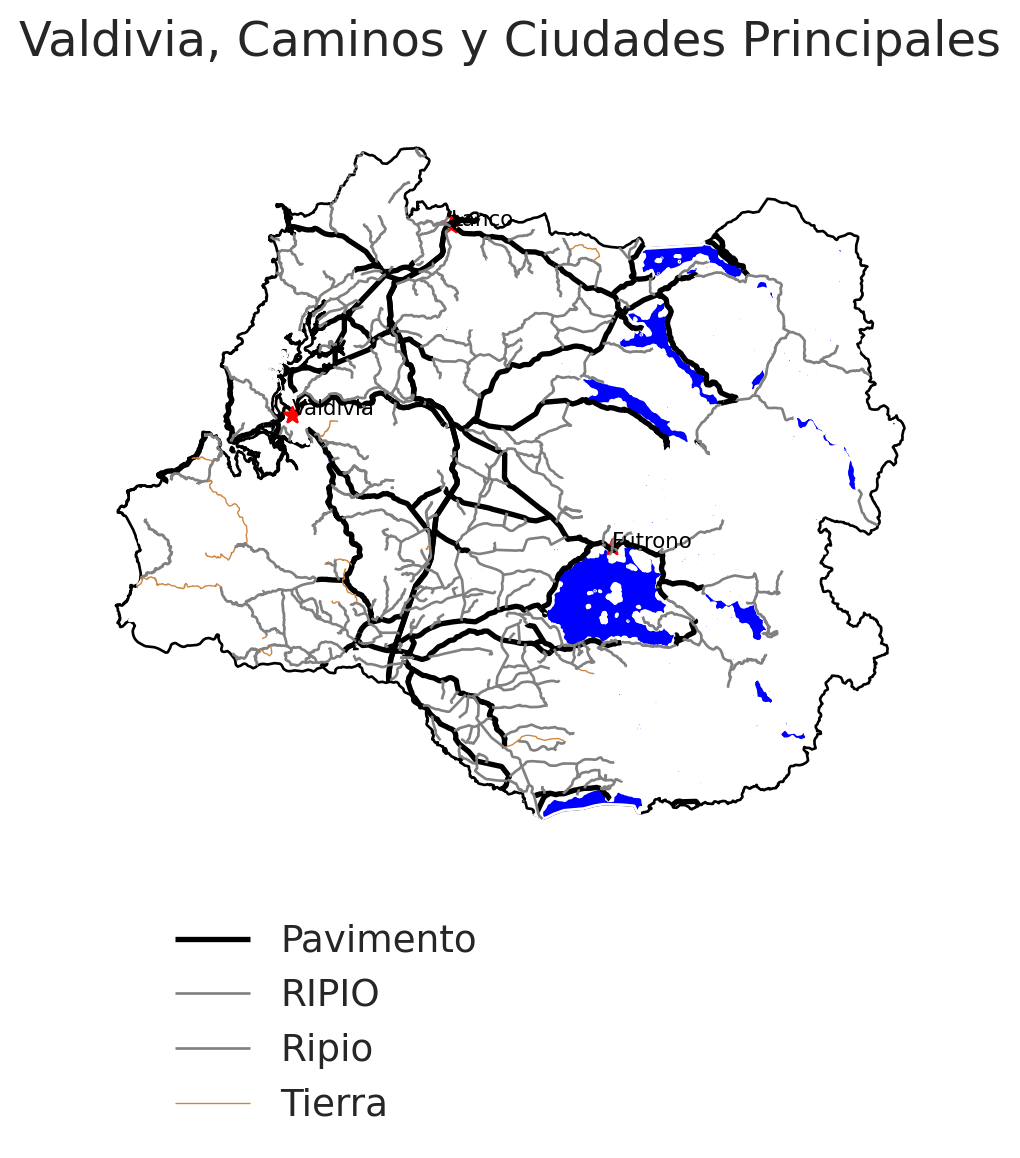
En el contexto de gráficos destinados a publicaciones dentro de revistas o artículos científicos, 300 dpi (puntos por pulgada) se ha considerado como el estándar para la calidad de imágenes. Podemos definir este parámetro dentro de plt.subplots().
Para mejorar la claridad de nuestra figura final, eliminaremos la Ciudad de Valdivia dentro de intersección_pobladas para evitar que interfiera con la visualización. En este caso, el filtrado se aplicará de una manera diferente: en lugar de generar un nuevo objeto con las ciudades de interés, realizaremos el filtrado directamente en la línea del gráfico. Esto nos permite hacer el ajuste “al vuelo” sin necesidad de generar un objeto adicional.
Tambien, le quitaremos el fondo a las etiquetas y agrandaremos el tamaño de las letras.
Por último, gracias a fig.savefig, podremos guardar nuestra figura para visualizarla con 300 dpi.
fig, ax = plt.subplots()
los_rios.plot(ax = ax,
color = "white",
edgecolor='black')
masas_lacustres.plot(ax = ax,
color = "blue")
interseccion_pobladas.plot(ax = ax,
marker = "*",
color = "red")
for tipo_caminos, data in caminos_lr.groupby("Tipo_Carpe"):
color = caminos_colores[tipo_caminos]
label = tipo_caminos
data.plot(color = color,
ax = ax,
linewidth = caminos_grosor[tipo_caminos],
label = label)
# Ciudades =========
for x, y, label in zip(interseccion_pobladas[interseccion_pobladas["Nombre"] != "Ciudad de Valdivia"].geometry.x, # Quitamos el objeto Ciudad de Valdivia
interseccion_pobladas[interseccion_pobladas["Nombre"] != "Ciudad de Valdivia"].geometry.y,
interseccion_pobladas[interseccion_pobladas["Nombre"] != "Ciudad de Valdivia"]['Nombre']):
ax.text(x,
y,
label,
fontsize = 8,
color = 'black')
# Fin Ciudades =========
ax.set_axis_off()
ax.legend(fontsize = 14,
frameon = False,
bbox_to_anchor=(0.5, -0.05))
plt.title("Valdivia, Caminos y Ciudades Principales")
fig.savefig("figura_300dpi.png", dpi=300)
plt.show()