Cuando se trabajan datos geoespaciales, es común realizar operaciones basadas en la ubicación de los elementos. Estas operaciones o consultas, pueden ir desde conocer la cantidad de puntos que se encuentran en una determinada zona, o donde caminos se intersectan con cursos de agua. Este tipo de operaciones se denominan consultas espaciales y son usadas para responder a preguntas basadas en las geometrías y posiciones de los elementos.
Para comenzar, descargaremos una capa comunal de Los Ríos junto con una capa de toponimia.
Primero, cargamos las librerías:
# Importando los paquetes necesarios
import os
os.environ['USE_PYGEOS'] = '0'
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import geopandas as gpd
import earthpy as et
import pandas as pd
import warnings
warnings.filterwarnings('ignore', 'GeoSeries.notna', UserWarning)
sns.set_style("white")
sns.set(font_scale = 1.5)
/usr/share/miniconda/envs/tallerpython/lib/python3.10/site-packages/earthpy/__init__.py:7: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
from pkg_resources import resource_string
Se descargan las capas con el siguiente link:
et.data.get_data(url = "https://figshare.com/ndownloader/files/49912008")
Se cargan las capas:
toponimia_path = os.path.join(et.io.HOME, 'earth-analytics',
"data", "earthpy-downloads",
"clase11", "toponimia_los_rios.shp")
toponimia = gpd.read_file(toponimia_path)
comunas_path = os.path.join(et.io.HOME, 'earth-analytics',
"data", "earthpy-downloads",
"clase11", "comuna_val.gpkg")
comuna = gpd.read_file(comunas_path)
En este caso comuna_val.gpkg contiene una capa. En el caso que el contenedor .gpkg posea más de una capa, sería necesario explorarlo con fiona y seleccionar la capa correspondiente con gpd.read_file().
Antes de comenzar, revisemos si ambas capas están en el mismo CRS:
Código
print(f"{comuna.crs == toponimia.crs}\n"
f"La capa comuna esta en el crs {comuna.crs} y la de toponimia esta en {toponimia.crs}")
Reproyectemos la capa de las comunas (de ser necesario):
Código
comuna_repro = comuna.to_crs(epsg = 32719)
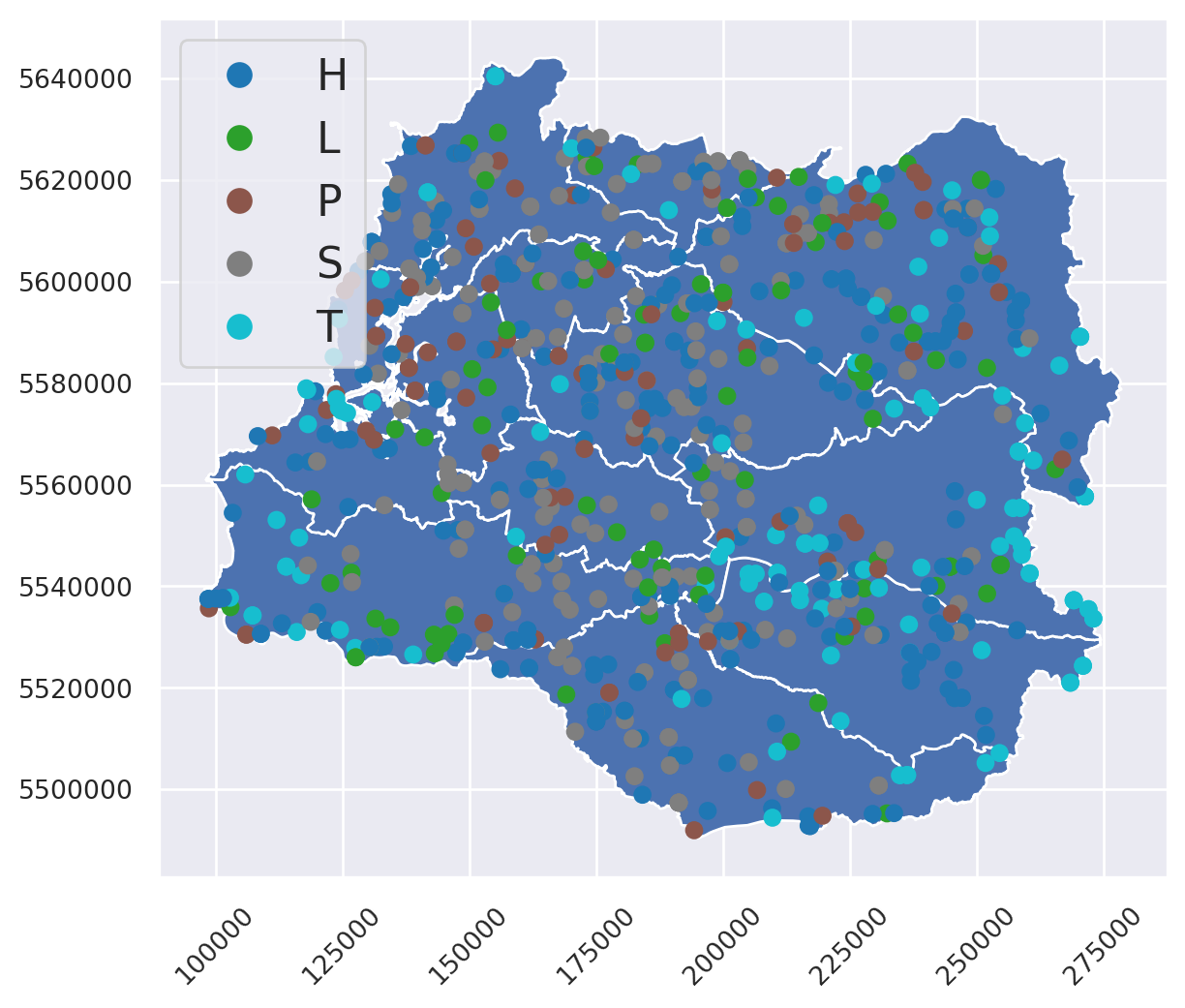
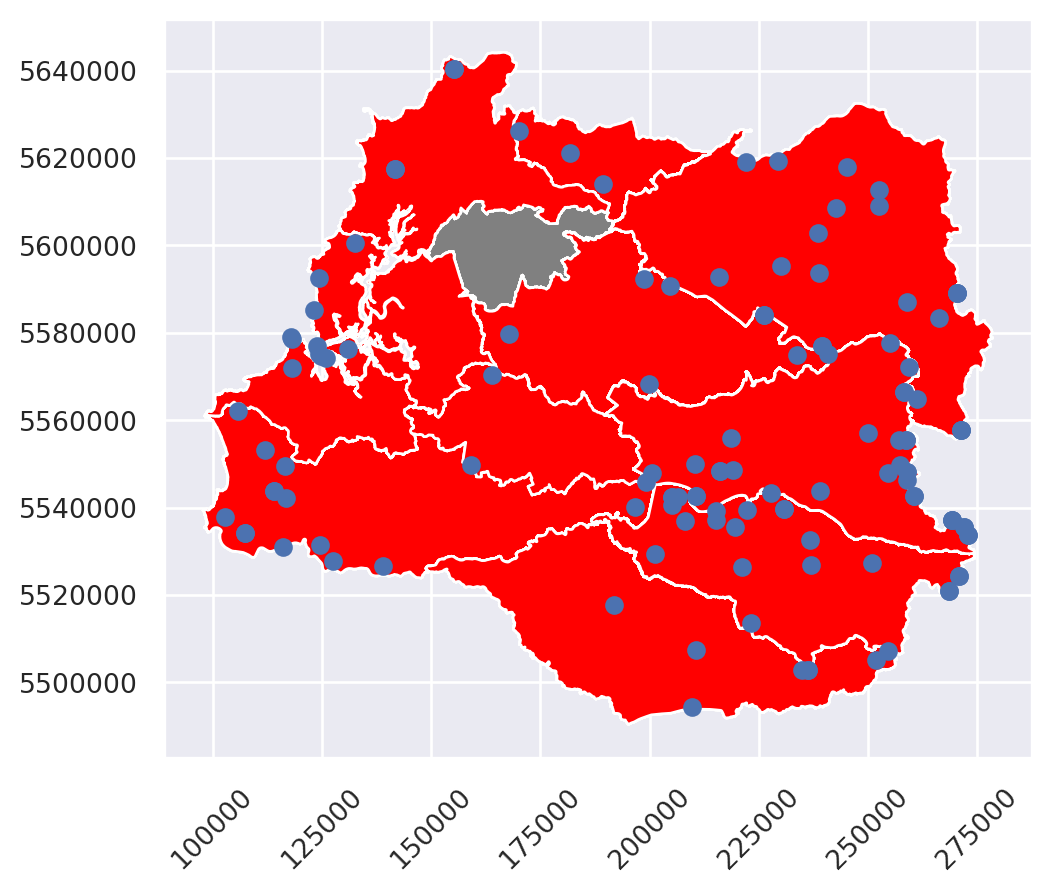
Realicemos un gráfico exploratorio:
Código
f, ax = plt.subplots(figsize=(9, 6))
comuna_repro.plot(ax = ax)
toponimia.plot(ax = ax,
column = "fc",
legend = True)
ax.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax.tick_params(axis = "y",
labelsize = 10)
ax.ticklabel_format(style='plain')
plt.show()
El atributo fc del objeto toponimia corresponde al código de la clase de toponimia que es. Nos enfocaremos en los objetos tipo T, que corresponden a elementos del relieve.
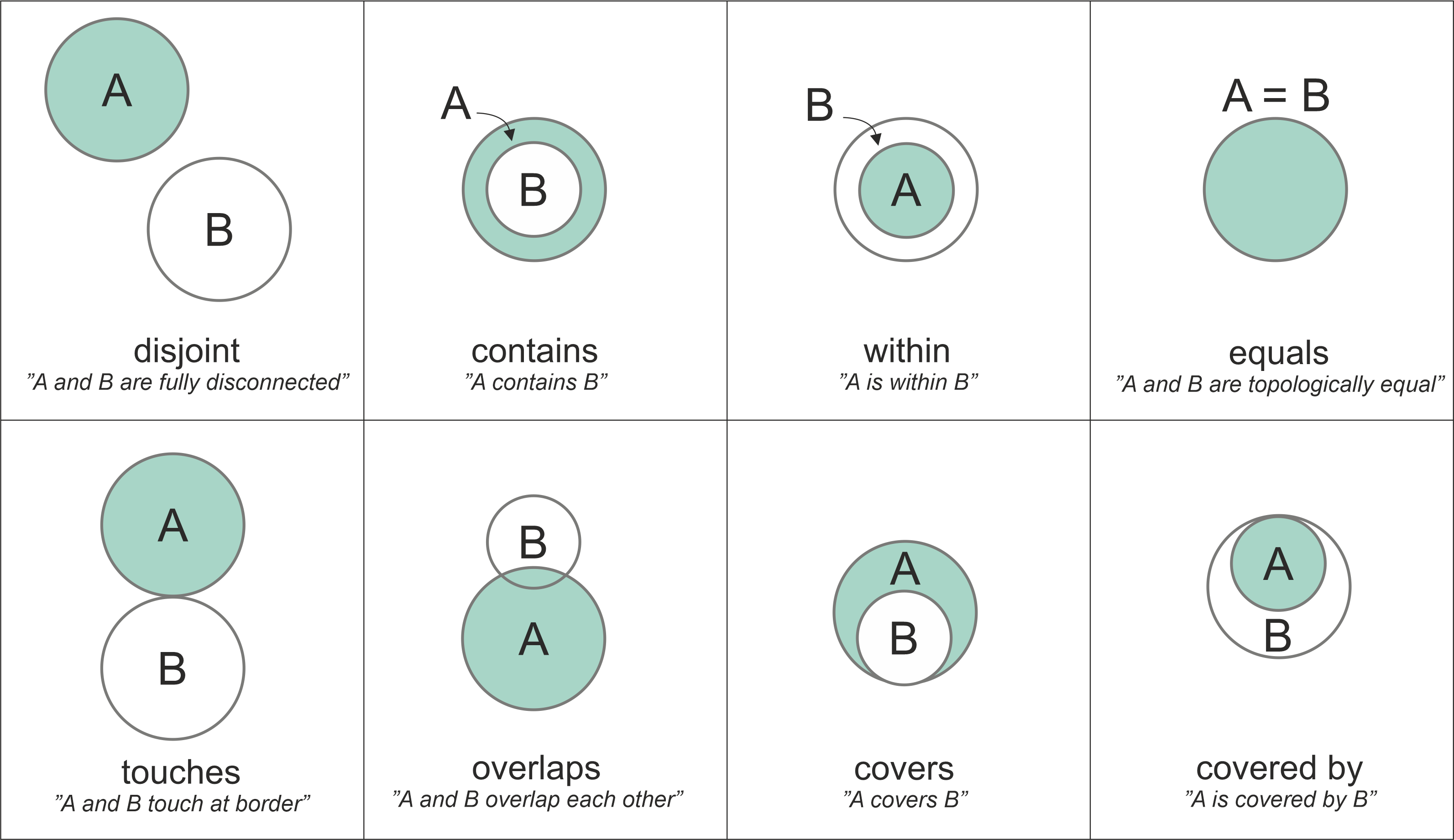
Relaciones espaciales comunes
En general, los SIG cuentan con ocho relaciones que comúnmente se utilizan para el análisis espacial.
En particular:
Separación (disjoint): Los elementos se encuentra separados, sin ninguna area en comun.
Contiene (contains): Un elemento contiene al otro.
Dentro (within): Un elemento se encuentra contenido dentro de otro.
Igual (equals): Los elementos son iguales.
Tocan(touches): Dos elementos se tocan cuando tienen un punto en comun, pero sus interiores no intersectan entre si.
Sobreponen (overlaps): Ambos objetos se sobreponen, en algún tipo de grado, sin embargo, poseen regiones sin sobrelape.
Cubre (covers): Un objeto cubre a otro (al igual que within) pero comparten al menos una coordenada en el borde. De manera similar, cubierto por (covered by) un objeto es cubierto por otro compartiendo un borde.
Cabe destacar que cuando dos objetos tienen al menos un punto en comun, se puede decir que intersectan entre si.
Para realizar consultas espaciales GeoPandas puede comparar fácilmente objetos espaciales gracias a .sjoin() (spatial join). En este caso, los parámetros serán:
Un índice espacial es una estructura de datos diseñado para realizar consultas espaciales de manera eficiente. En este caso, GeoPandas ocupa un índice llamado árbol-R. Este método maneja eficientemente consultas para datos voluminosos.
Para ver todas las posibles consultas espaciales se puede consultar .sindex.valid_query_predicates:
comuna.sindex.valid_query_predicates
{None,
'contains',
'contains_properly',
'covered_by',
'covers',
'crosses',
'dwithin',
'intersects',
'overlaps',
'touches',
'within'}
Dentro within
En este ejemplo, queremos consultar cuales elementos del relieve (puntos o accidentes geográficos) se encuentran dentro de las comunas de Lanco, Mariquina, Panguipulli y Máfil. Para ir alternando entre tipos de consultas, se cambia el argumento predicate dentro de la función .sjoin(). Para el caso de este ejemplo, la operación sería "within".
Primero, creemos los dos objetos, las comunas y los puntos del relieve:
Para la capa de toponimia:
topo_filt = toponimia[toponimia["fc"] == "T"]
topo_filt.head()
| 14 |
T |
14202.0 |
Cerro Cuerno de Chihuihue |
Elementos del Relieve |
POINT (258569.332 5555435.884) |
| 16 |
T |
14101.0 |
Punta Loncoyen |
Elementos del Relieve |
POINT (123283.532 5585161.193) |
| 30 |
T |
14104.0 |
Cerro El Mocho |
Elementos del Relieve |
POINT (240829.077 5575226.254) |
| 57 |
T |
14201.0 |
Punta Munulmo |
Elementos del Relieve |
POINT (199198.448 5545895.728) |
| 60 |
T |
14202.0 |
Cerros de Panguilelfu |
Elementos del Relieve |
POINT (258215.682 5566537.341) |
Debido a que las comunas de interés son varias, podemos filtrar el objeto con otro enfoque. Se puede ocupar el indexador .loc y dentro de este, mostrar los elementos que nos interesa con .isin(). Dentro de este último, se acepta una lista con los nombres a ocupar.
comu_filt = comuna_repro.loc[comuna_repro["Comuna"].isin(["Máfil", "Panguipulli", "Lanco", "Mariquina"])]
comu_filt
| 2 |
144 |
181074.022363 |
24 |
12 |
14105 |
14 |
9.787385e+08 |
235205.534329 |
Región de Los Ríos |
Máfil |
Valdivia |
MULTIPOLYGON (((160721.165 5610078.26, 160831.... |
| 4 |
142 |
152128.428573 |
24 |
12 |
14103 |
14 |
8.938992e+08 |
196801.580866 |
Región de Los Ríos |
Lanco |
Valdivia |
MULTIPOLYGON (((173602.848 5630892.575, 173670... |
| 5 |
147 |
360175.439414 |
24 |
12 |
14108 |
14 |
5.576570e+09 |
491691.411153 |
Región de Los Ríos |
Panguipulli |
Valdivia |
MULTIPOLYGON (((267028.818 5607806.463, 267026... |
| 7 |
145 |
368604.512461 |
24 |
12 |
14106 |
14 |
2.181621e+09 |
481915.542171 |
Región de Los Ríos |
Mariquina |
Valdivia |
MULTIPOLYGON (((135493.418 5624749.444, 135503... |
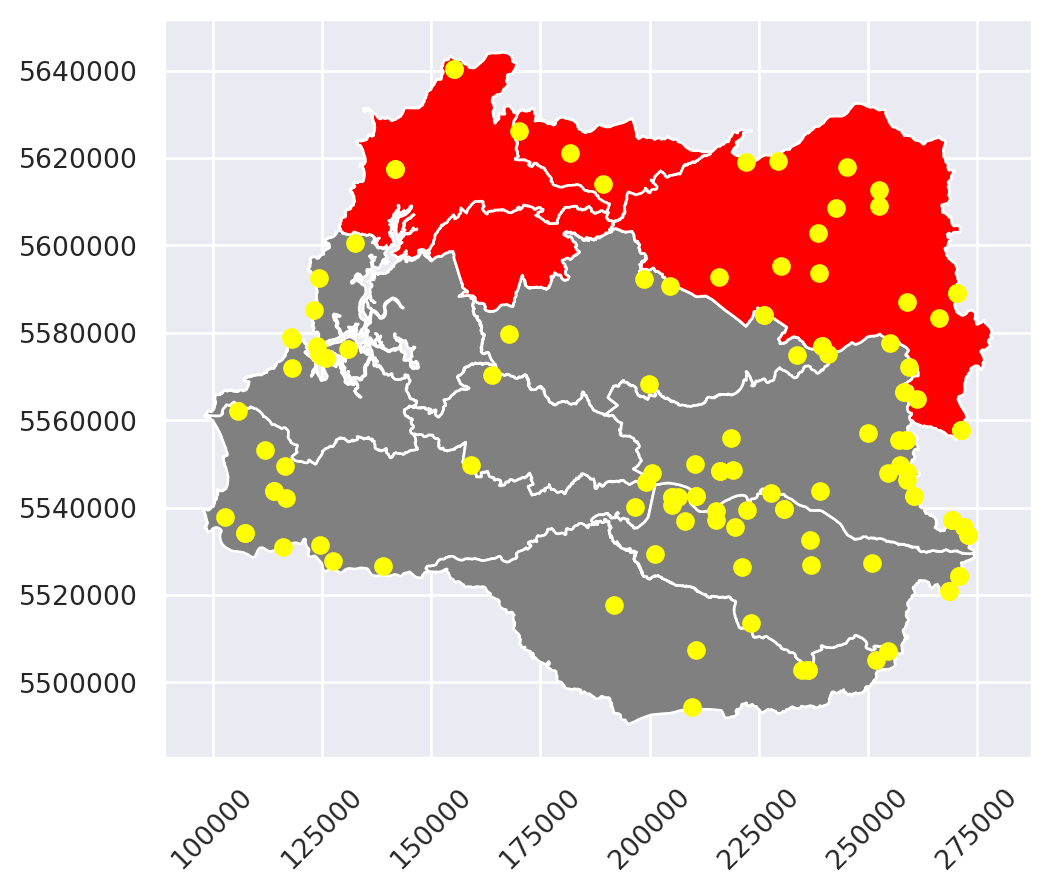
Para inspeccionar el filtrado, grafiquemos los resultados:
fig, ax = plt.subplots()
# Mapa base
comuna_repro.plot(ax = ax,
color = "grey")
# Las comunas filtrados
comu_filt.plot(ax = ax,
color = "red")
# Elemenos del relieve
topo_filt.plot(ax = ax,
color = "yellow")
ax.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax.tick_params(axis = "y",
labelsize = 10)
ax.ticklabel_format(style='plain')
plt.show()
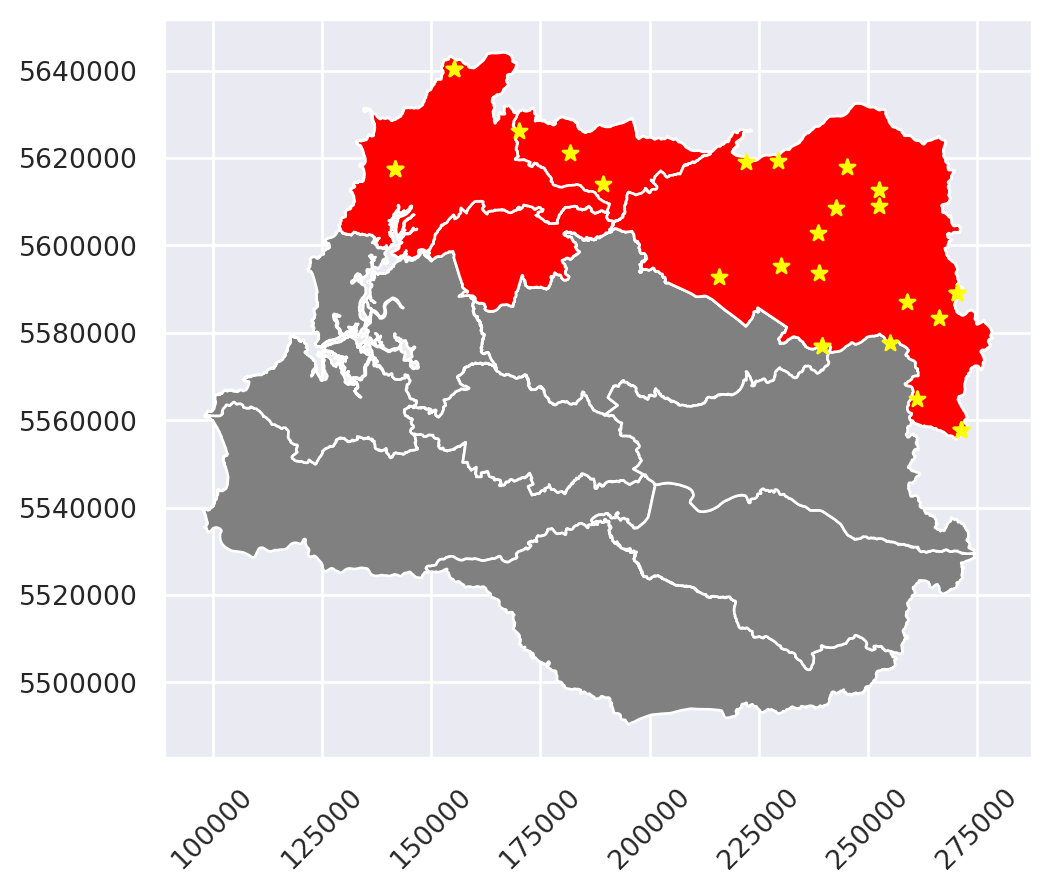
Ahora con estas capas haremos la consulta:
puntos_sel = topo_filt.sjoin(comu_filt.geometry.to_frame(),
predicate = "within")
En este caso, del objeto comu_filt, seleccionamos su geometría con .geometry y transformamos en un GeoDataFrame de GeoPandas.
Finalmente ploteamos para ver los puntos:
fig, ax = plt.subplots()
# Mapa base
comuna_repro.plot(ax = ax,
color = "grey")
# Las comunas filtrados
comu_filt.plot(ax = ax,
color = "red")
# Elemenos del relieve
puntos_sel.plot(ax = ax,
color = "yellow",
marker = "*")
ax.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax.tick_params(axis = "y",
labelsize = 10)
ax.ticklabel_format(style='plain')
plt.show()
Contener (contains)
De igual manera podemos investigar cuantos polígonos tienen al menos un punto en su interior. Para esto usamos contains como un parámetro dentro de .sjoin():
comunas_sel = comuna_repro.sjoin(topo_filt.geometry.to_frame(),
predicate = "contains")
Graficamos:
fig, ax = plt.subplots()
# Mapa base
comuna_repro.plot(ax = ax,
color = "grey")
# Las comunas filtrados
comunas_sel.plot(ax = ax,
color = "red")
# Elemenos del relieve
topo_filt.plot(ax = ax)
ax.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax.tick_params(axis = "y",
labelsize = 10)
ax.ticklabel_format(style='plain')
plt.show()
Método sjoin
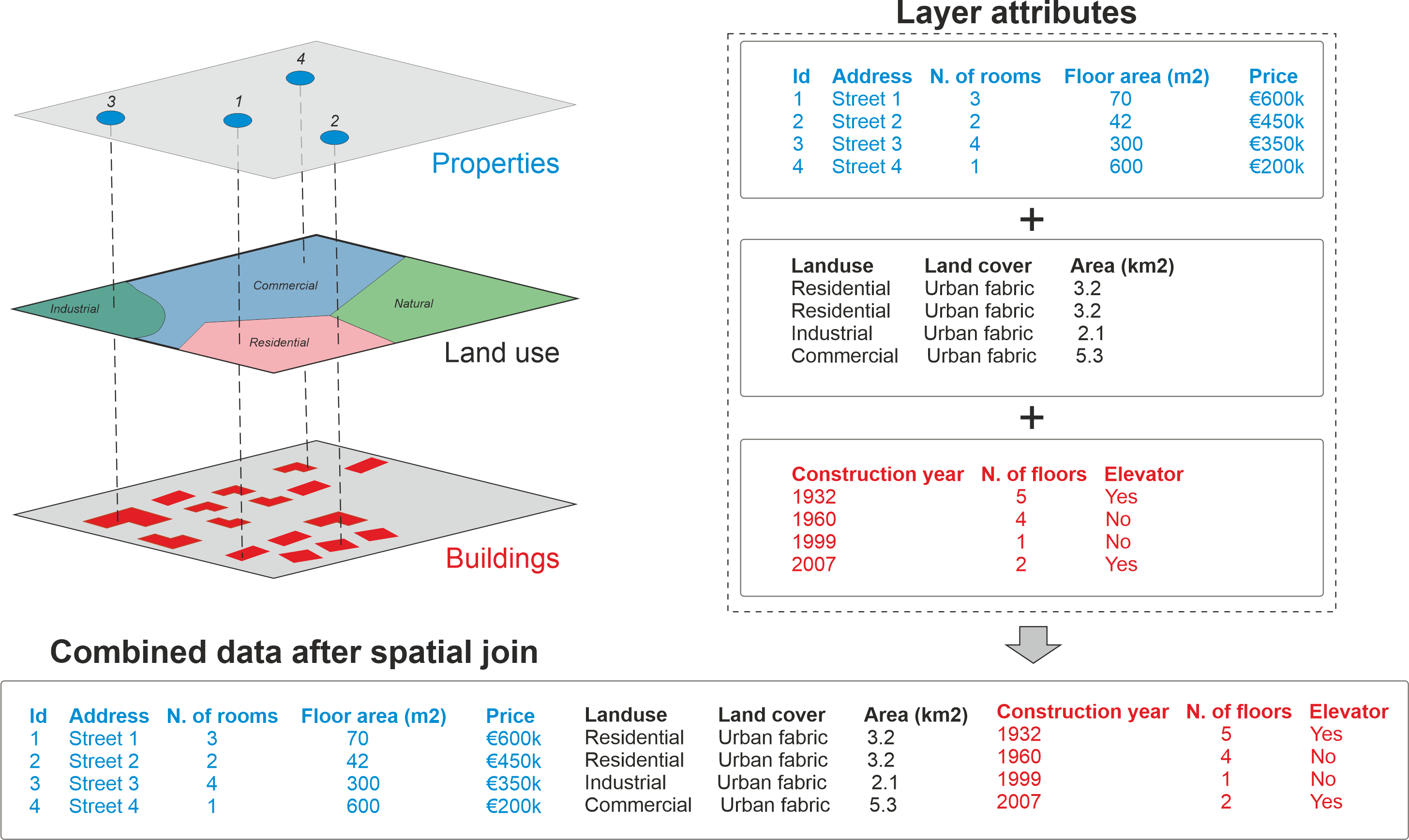
Si bien, ocupamos el método .sjoin() para realizar consultas espaciales entre distintos objetos, esta función es capaz de transferir la información de una capa a otras. Esto resulta especialmente útil cuando deseamos agregar atributos de una capa geoespacial (como una capa de puntos de interés o límites administrativos) a otra, basándonos en su interacción espacial. Así, podemos tener más atributos que permiten ampliar las opciones de análisis con la información. Esta imagen ilustra los procesos asociados:
En este caso, sjoin tiene esta sintáxis:
gdf1.sjoin(gdf2, how = , predicate = )
Además, tiene dos parámetros principales:
predicate = La relación entre capas (como contiene, intersecta). Este entrega los valores que cumplan con la consulta deseada.
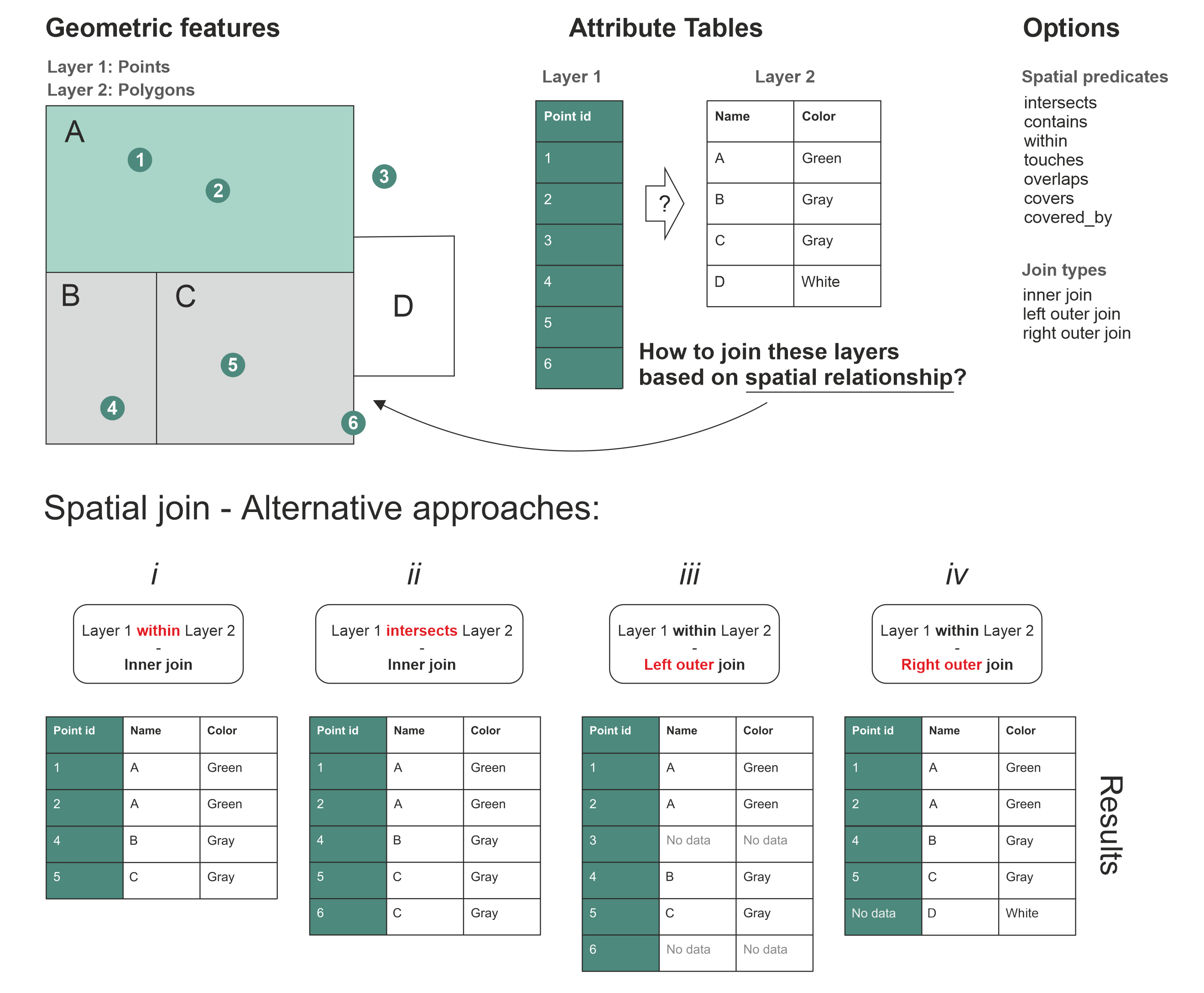
how = Como GeoPandas maneja las coincidencias espaciales entre ambos GeoDataFrames. Dentro de este existen tres tipos de uniones:
inner: Mantiene las filas de la tabla de atributos en donde gdf1 y gdf2 coincidan (según la consulta que se hace). Los valores que no cumplan con esto se descartan.left: Unión a la izquierda. Esto quiere decir que mantiene todas las filas de GeoDataFrame de la izquierda (en este caso gdf1) y añade las columnas del gdf2 donde haya coincidencia espacial. Si no se encuentra dicha coincidencia, los valores serán NaN.right: Unión a la derecha. Similar al caso anterior, se mantienen los atributos de gdf2 y se añaden las columnas de gdf1 donde haya coincidencias espaciales. De no existir, se rellena con NaN.
Esto puede ejemplificarse con la siguiente imagen
Si inspeccionamos la capa de toponimia, observamos que esta solo contiene la clase de toponimia, su código, el nombre del objeto y el código de la comuna. Sin embargo, no tenemos información sobre a qué comuna y provincia pertenecen los puntos. Como ejemplo, supongamos que queremos identificar a qué comuna pertenecen los puntos de toponimia relacionados con las redes hidrográficas (codificados como H dentro de fc). Para ello, podemos consultar cuántos puntos se encuentran dentro de las comunas y conservar los datos donde esta condición se cumpla:
Primero seleccionamos los puntos de redes hidrográficas:
puntos_hidro = toponimia[toponimia["fc"] == "H"]
Posteriormente, aplicamos la función:
hidro_valdivia_inner = puntos_hidro.sjoin(comuna_repro,
predicate = "within",
how = "inner")
hidro_valdivia_inner.info()
<class 'geopandas.geodataframe.GeoDataFrame'>
Index: 276 entries, 0 to 841
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 fc 276 non-null object
1 cod_comuna_left 276 non-null float64
2 Nombre 276 non-null object
3 Clase_Topo 276 non-null object
4 geometry 276 non-null geometry
5 index_right 276 non-null int64
6 objectid 276 non-null int64
7 shape_leng 276 non-null float64
8 dis_elec 276 non-null int32
9 cir_sena 276 non-null int32
10 cod_comuna_right 276 non-null int32
11 codregion 276 non-null int32
12 st_area_sh 276 non-null float64
13 st_length_ 276 non-null float64
14 Region 276 non-null object
15 Comuna 276 non-null object
16 Provincia 276 non-null object
dtypes: float64(4), geometry(1), int32(4), int64(2), object(6)
memory usage: 34.5+ KB
Podemos observar que los datos contienen columnas provenientes de ambas capas. Además, es posible inspeccionar el elemento resultante:
hidro_valdivia_inner.head()
| 0 |
H |
14104.0 |
Estero Cusilelfu |
Red Hidrografica |
POINT (189924.253 5599273.111) |
1 |
143 |
316586.233799 |
24 |
12 |
14104 |
14 |
3.042426e+09 |
412407.032880 |
Región de Los Ríos |
Los Lagos |
Valdivia |
| 1 |
H |
14106.0 |
Estero Venados |
Red Hidrografica |
POINT (147202.115 5625246.095) |
7 |
145 |
368604.512461 |
24 |
12 |
14106 |
14 |
2.181621e+09 |
481915.542171 |
Región de Los Ríos |
Mariquina |
Valdivia |
| 3 |
H |
14108.0 |
Estero Nalalguaca |
Red Hidrografica |
POINT (196706.552 5608810.225) |
5 |
147 |
360175.439414 |
24 |
12 |
14108 |
14 |
5.576570e+09 |
491691.411153 |
Región de Los Ríos |
Panguipulli |
Valdivia |
| 5 |
H |
14104.0 |
Estero Laurana |
Red Hidrografica |
POINT (164761.628 5585237.243) |
2 |
144 |
181074.022363 |
24 |
12 |
14105 |
14 |
9.787385e+08 |
235205.534329 |
Región de Los Ríos |
Máfil |
Valdivia |
| 6 |
H |
14108.0 |
Lago Quilmo |
Red Hidrografica |
POINT (257673.171 5592386.031) |
5 |
147 |
360175.439414 |
24 |
12 |
14108 |
14 |
5.576570e+09 |
491691.411153 |
Región de Los Ríos |
Panguipulli |
Valdivia |
Sin embargo, si comparamos el largo del objeto resultante junto con los puntos originales, podemos notar que estos no coinciden:
len(hidro_valdivia_inner) == len(puntos_hidro)
print(f"El largo de los puntos originales es de {len(puntos_hidro)} y de la capa resultante es de {len(hidro_valdivia_inner)}")
El largo de los puntos originales es de 282 y de la capa resultante es de 276
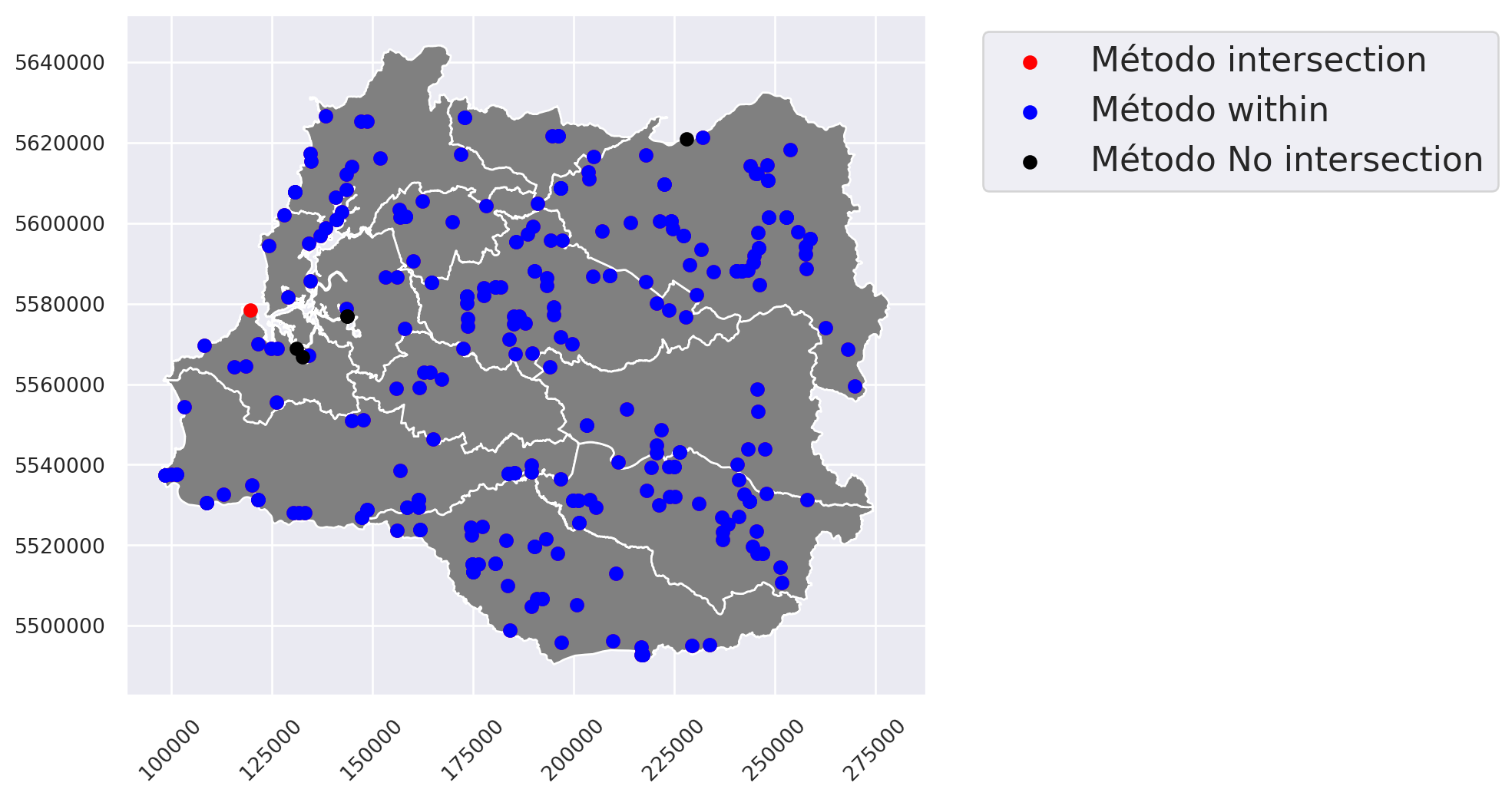
Esto ocurre porque algunos puntos no están completamente al interior de los polígonos, sino que una parte de ellos queda fuera. Además, puede suceder que algunos puntos no se encuentren en ningún polígono de las comunas, lo que genera la diferencia. Podemos resolver esto realizando consultas con el predicado espacial intersects y cambiando los parámetros para usar how.
Intentemos ver los puntos que intersectan a los polígonos:
puntos_interseccion = puntos_hidro.sjoin(comuna_repro,
predicate = "intersects",
how = "inner")
len(puntos_interseccion)
En este caso, obtuvimos un punto extra a diferencia del método within.
Ahora busquemos los puntos que no se interceptan con los polígonos. Para esto, mantendremos el predicado intersects, pero mantendremos la tabla de atributos de la capa de puntos. Esto provocará que elementos que no se encuentren dentro de una comuna se completen con NaN. Luego podemos usar este atributo para filtrar:
puntos_no_intersec = puntos_hidro.sjoin(comuna_repro,
how='left',
predicate='intersects')
puntos_no_intersec.head()
| 0 |
H |
14104.0 |
Estero Cusilelfu |
Red Hidrografica |
POINT (189924.253 5599273.111) |
1.0 |
143.0 |
316586.233799 |
24.0 |
12.0 |
14104.0 |
14.0 |
3.042426e+09 |
412407.032880 |
Región de Los Ríos |
Los Lagos |
Valdivia |
| 1 |
H |
14106.0 |
Estero Venados |
Red Hidrografica |
POINT (147202.115 5625246.095) |
7.0 |
145.0 |
368604.512461 |
24.0 |
12.0 |
14106.0 |
14.0 |
2.181621e+09 |
481915.542171 |
Región de Los Ríos |
Mariquina |
Valdivia |
| 3 |
H |
14108.0 |
Estero Nalalguaca |
Red Hidrografica |
POINT (196706.552 5608810.225) |
5.0 |
147.0 |
360175.439414 |
24.0 |
12.0 |
14108.0 |
14.0 |
5.576570e+09 |
491691.411153 |
Región de Los Ríos |
Panguipulli |
Valdivia |
| 5 |
H |
14104.0 |
Estero Laurana |
Red Hidrografica |
POINT (164761.628 5585237.243) |
2.0 |
144.0 |
181074.022363 |
24.0 |
12.0 |
14105.0 |
14.0 |
9.787385e+08 |
235205.534329 |
Región de Los Ríos |
Máfil |
Valdivia |
| 6 |
H |
14108.0 |
Lago Quilmo |
Red Hidrografica |
POINT (257673.171 5592386.031) |
5.0 |
147.0 |
360175.439414 |
24.0 |
12.0 |
14108.0 |
14.0 |
5.576570e+09 |
491691.411153 |
Región de Los Ríos |
Panguipulli |
Valdivia |
Elaboramos el filtro:
puntos_no_intersec = puntos_no_intersec[puntos_no_intersec['index_right'].isna()]
Finalmente graficamos para
fig, ax = plt.subplots(figsize=(9, 6))
comuna_repro.plot(ax = ax,
color = "grey")
puntos_interseccion.plot(ax = ax,
color = "red",
label = "Método intersection")
hidro_valdivia_inner.plot(ax = ax,
color = "blue",
label = "Método within")
puntos_no_intersec.plot(ax = ax,
color = "black",
label = "Método No intersection")
ax.legend(loc = 'upper left',
bbox_to_anchor = (1.05, 1))
ax.tick_params(axis = "x",
labelsize = 10,
labelrotation = 45)
ax.tick_params(axis = "y",
labelsize = 10)
ax.ticklabel_format(style='plain')
plt.show()
Unión a partir de un atributo en común
Además de realizar uniones mediante geometrías, también se puede realizar por atributos. Para esto, podemos unir GeoDataFrames con DataFrames y así expandir nuestra base de datos vectorial. Para ello, ambos objetos deben compartir un atributo en común que permita unirlos. Para lograr esto, utilizamos la función merge, que es un método dentro de Pandas. Algunos de sus parámetros son:
right =: El otro DataFrame o GeoDataFrame con el que se realizará la unión.
how =: Similar a sjoin(), define cómo se tratarán los datos con coincidencias (en este caso, dentro de la tabla de atributos).
on =: La columna común con la que se realizará la unión. Ambos DataFrames deben tener la misma columna con el mismo nombre.
left_on =: Si no comparten el mismo nombre de columna, se puede especificar la columna del DataFrame de la izquierda que se usará para la unión.
right_on =: Similar al anterior, pero en este caso se refiere a la columna del DataFrame de la derecha.
Como ejemplo, supongamos que queremos saber la cantidad de personas en los principales centros poblados de la región (codificados como P dentro del atributo sf en toponimia). Para lograrlo, cargaremos un archivo .csv desde internet con los datos censales de Chile (año 2017) y lo uniremos con la capa de puntos.
Primero, creamos la capa de ciudades:
ciudades = toponimia[toponimia["fc"] == "P"]
Luego, cargamos el DataFrame con los datos censales:
censo = pd.read_csv(filepath_or_buffer = "https://raw.githubusercontent.com/Aloniss/datosGeoPython2024/refs/heads/main/censo_tabla.csv")
Revisemos los datos para ver si comparten algún atributo en común:
| 0 |
15 |
151 |
15101 |
REGIÓN DE ARICA Y PARINACOTA |
ARICA |
ARICA |
72639 |
72414 |
225 |
221364 |
109389 |
111975 |
46.2 |
97.7 |
48.9 |
32.7 |
16.2 |
385226.621813 |
5.362876e+09 |
| 1 |
15 |
151 |
15102 |
REGIÓN DE ARICA Y PARINACOTA |
ARICA |
CAMARONES |
948 |
927 |
21 |
1255 |
726 |
529 |
0.3 |
137.2 |
46.8 |
22.7 |
24.1 |
415486.324962 |
4.424112e+09 |
| 2 |
15 |
152 |
15201 |
REGIÓN DE ARICA Y PARINACOTA |
PARINACOTA |
PUTRE |
1917 |
1875 |
42 |
2765 |
2054 |
711 |
0.5 |
288.9 |
21.3 |
11.0 |
10.3 |
436546.355816 |
6.578891e+09 |
| 3 |
15 |
152 |
15202 |
REGIÓN DE ARICA Y PARINACOTA |
PARINACOTA |
GENERAL LAGOS |
697 |
686 |
11 |
684 |
412 |
272 |
0.3 |
151.5 |
41.9 |
21.4 |
20.5 |
258714.907928 |
2.504780e+09 |
| 4 |
1 |
11 |
1101 |
REGIÓN DE TARAPACÁ |
IQUIQUE |
IQUIQUE |
66986 |
66725 |
261 |
191468 |
94897 |
96571 |
83.7 |
98.3 |
43.8 |
30.5 |
13.3 |
439871.457090 |
2.636780e+09 |
| 4 |
P |
14108.0 |
Traitraico |
Centro Poblado |
POINT (239324.942 5619631.614) |
| 10 |
P |
14106.0 |
Quechupulli |
Centro Poblado |
POINT (170551.126 5617005.18) |
| 13 |
P |
14106.0 |
Pelchuquin |
Centro Poblado |
POINT (150909.012 5606870.54) |
| 23 |
P |
14107.0 |
Paillaco |
Centro Poblado |
POINT (168825.467 5557603.383) |
| 26 |
P |
14108.0 |
Pullingue |
Centro Poblado |
POINT (226496.173 5617335.675) |
Note que censo tiene la columna COMUNA (como código) y ciudades tiene el código de la comuna bajo cod_comuna. Con esta información, podemos realizar la fusión:
ciudades_censo = ciudades.merge(censo,
how = "inner",
left_on = "cod_comuna",
right_on = "COMUNA")
| 0 |
P |
14108.0 |
Traitraico |
Centro Poblado |
POINT (239324.942 5619631.614) |
14 |
141 |
14108 |
REGIÓN DE LOS RÍOS |
VALDIVIA |
... |
34539 |
17199 |
17340 |
10.5 |
99.2 |
51.9 |
32.4 |
19.5 |
461350.409184 |
5.579646e+09 |
| 1 |
P |
14106.0 |
Quechupulli |
Centro Poblado |
POINT (170551.126 5617005.18) |
14 |
141 |
14106 |
REGIÓN DE LOS RÍOS |
VALDIVIA |
... |
21278 |
10607 |
10671 |
16.4 |
99.4 |
55.4 |
36.5 |
18.8 |
470782.728578 |
2.180760e+09 |
| 2 |
P |
14106.0 |
Pelchuquin |
Centro Poblado |
POINT (150909.012 5606870.54) |
14 |
141 |
14106 |
REGIÓN DE LOS RÍOS |
VALDIVIA |
... |
21278 |
10607 |
10671 |
16.4 |
99.4 |
55.4 |
36.5 |
18.8 |
470782.728578 |
2.180760e+09 |
| 3 |
P |
14107.0 |
Paillaco |
Centro Poblado |
POINT (168825.467 5557603.383) |
14 |
141 |
14107 |
REGIÓN DE LOS RÍOS |
VALDIVIA |
... |
20188 |
10067 |
10121 |
22.4 |
99.5 |
51.9 |
31.6 |
20.3 |
261851.037352 |
1.541040e+09 |
| 4 |
P |
14108.0 |
Pullingue |
Centro Poblado |
POINT (226496.173 5617335.675) |
14 |
141 |
14108 |
REGIÓN DE LOS RÍOS |
VALDIVIA |
... |
34539 |
17199 |
17340 |
10.5 |
99.2 |
51.9 |
32.4 |
19.5 |
461350.409184 |
5.579646e+09 |
5 rows × 24 columns
Con estos métodos podemos enriquecer nuestras bases de datos vectoriales, empleando atributos provenientes de tablas externas que no requieren ser de naturaleza espacial.