8 Formato de texto para los Datos Ambientales
Existen muchos formatos de texto que son útiles para trabajar en flujos de trabajo incluyendo Markdown (que ya revisamos en el capítulo 4), texto (.csv, .txt) y YAML (Yet Another Markup Language).
8.1 Uso de datos tabulares para la Ciencia de datos Geoespaciales
Al final de esta lección podremos:
Definir la estructura de los datos tabulares.
Describir las diferencias entre dos tipos de datos tabulares de texto (
.txty.csv).Ser capaces de reconocer y listar algunos de los tipos de datos que se usan en la Ciencia y que a menudo son descargados en formato tabular.
¿Qué son los datos tabulares?
Son datos almacenados en un formato de filas/columnas. Las columnas (a veces también las filas) son a menudo identificadas por cabeceras, las cuales explican que hay en las filas o columnas. Esta estructura es ya conocida y puede resultar familiar si se ha trabajado con herramientas de planillas como Excel o Google que usan datos tabulares.
Estructura de los datos tabulares
En el ejemplo mostrado a continuación, se aprecia una tabla con valores que representa la precipitación para 3 días. Las cabeceras de los datos incluyen: día y precipitación-mm.
| día | precipitación-mm |
|---|---|
| Lunes | 0 |
| Martes | 2 |
| Miércoles | 5 |
Además, los datos contienen 4 filas, la primera de las cuales es la cabecera de la fila (fila 1) y las siguientes son las que contienen los datos. La tabla además, contiene 2 columnas.
Tipos comunes de datos tabulares: .txt y .csv
Como se mencionó anteriormente, los datos tabulares pueden ser descargados en diferentes formatos de archivos. Formatos de planillas como .xls o .xlsx pueden ser abiertas directamente en Excel. Sin embargo, cuando se están descargando datos de la Tierra, Recursos Naturales o Medio Ambiente, que a menudo provienen de sensores instalados en el campo o plataformas móviles, a menudo se ven datos tabulares almacenados en archivos que pueden incluir:
.csv: Archivos separados por coma. En este archivo cada columna ha sido separada o delimitada por una coma..txt: Archivos básicos de texto. En este tipo de archivos, los delimitadores pueden variar, siendo entre los carácteres más comunes el espacio, la tabulación y el punto y coma (;).
Estos tipos de archivos están basados en formato de texto y a menudo pueden ser abiertos en un editor como el Bloc de Notas o Notepad.
Uno de los principales desafíos cuando se trabaja con herramientas basadas en GUIs (Excel, Google Spreadsheet) es que a menudo ofrecen limitaciones cuando se requiere trabajar con datos de gran volumen. Se hace muy difícil recrear los flujos de trabajo implementados en Excel porque a menudo se hace necesaria interacción que se traduce en presionar botones. Es posible usar herramientas de fuente abierta como Python para implementar cualquier flujo de trabajo que podría estar en Excel y ese flujo sería totalmente intercambiable y reproducible.
Archivos de texto y delimitadores
Un delimitador se refiere a un caracter que define los límites para diferentes sets o grupos de información. En un archivo de texto, el delimitador define los límites entre las columnas. Un salto de línea (Enter) define cada fila.
Abajo se encuentra un ejemplo de un archivo de texto delimitado por comas. Cada columna de datos es separada por una coma (,). El archivo también incluye una cabecera que es separada por comas.
codigo_sitio, anio, mes, dia, hora, minuto, segundo, tiempo_decimal, valor, valor_desviacion_estandar
BRW, 1973,1,1,0,0,0,1973.0, -999.99, -99.99
BRW, 1973,2,1,0,0,0,1973.0849315068492, -999.99, -99.99
BRW, 1973,3,1,0,0,0,1973.1616438356164, -999.99, -99.99La imagen mostrada a continuación ilustra un archivo de texto que usa como delimitador un espacio simple ().
codigo_sitio anio mes dia hora minuto segundo tiempo_decimal valor valor_desviacion_estandar
BRW 1973 1 1 0 0 0 1973.0 -999.99 -99.99
BRW 1973 2 1 0 0 0 1973.0849315068492 -999.99 -99.99
BRW 1973 3 1 0 0 0 1973.1616438356164 -999.99 -99.99En consecuencia, hay varios caracteres que pueden definir un delimitador incluyendo:
Tabulaciones
Comas
Uno o más espacios
A veces es posible encontrar otros caracteres usados como delimitadores, pero los listados arriba son los más comunes.
8.2 Importación de datos a Python
Si bien Python permite trabajar con distintos tipos de datos (desde archivos de texto como .csv hasta formatos más complejos como JSON), estos deben ser importados y manipulados adecuadamente. Entre las bibliotecas más populares se encuentra Pandas, que está especializada en el análisis y manejo de estructuras de datos. Gracias a esta librería, es posible leer y editar archivos .csv, Excel y bases de datos SQL.
Para comenzar su uso, es necesario importar la librería, generalmente abreviada como pd:
Pandas maneja dos tipos de estructuras de datos:
Series: Estructura de datos unidimensional similar a una lista o un arreglo, que puede almacenar datos de cualquier tipo (números, texto, etc.) y está etiquetada con un índice. Cada elemento en una Serie está asociado a una etiqueta o índice, lo que facilita el acceso y la manipulación de los datos.DataFrame: Estructura bidimensional (tablas). Es el formato más común para los datos almacenados en archivos de texto. Cada columna en unDataFramees unaSerie, por lo que cada columna debe contener datos de un único tipo, mientras que las filas pueden contener registros con varios tipos de datos.
La estructura de un DataFrame se ejemplifica en la siguiente imagen:
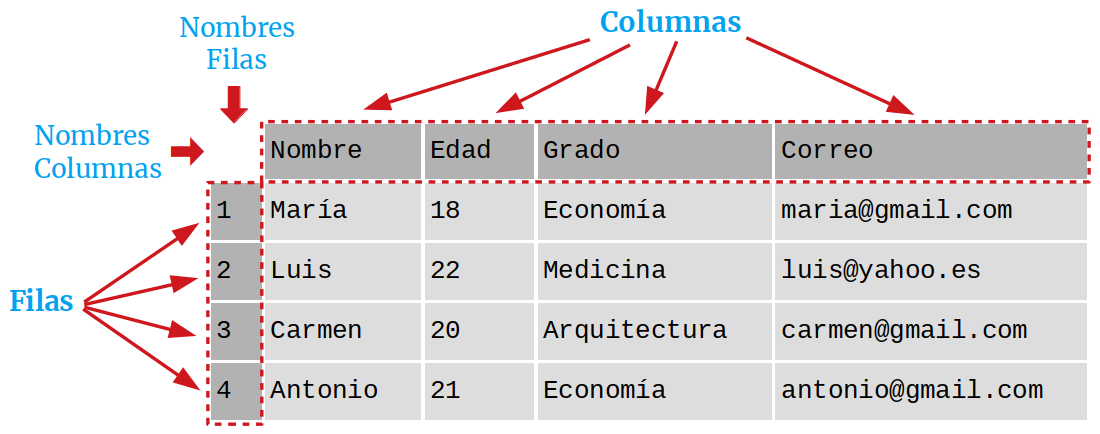
DataFrame de Pandas.
En esta estructura existen dos índices: uno para las filas y otro para las columnas, lo que permite acceder a los elementos del DataFrame mediante el nombre de las filas y columnas.
Construcción de DataFrames manuales
Existen varias formas de crear DataFrames desde cero (a través de diccionarios, arrays, entre otros). En este caso, construiremos una tabla a partir de una lista. Primero, creamos las listas que representarán los valores de cada columna.
Para crear un objeto DataFrame, se utiliza la función DataFrame del módulo pd, siguiendo esta sintaxis:
pd.DataFrame(): Inicia la función.data =: Parámetro que puede contenerSeries, arrays, constantes o listas. Es importante mencionar que solo acepta una lista.columns =: Indica los nombres de las columnas. Se puede estructuras similares a arrays (como una lista).index =: Objeto del tipoIndexque puede añadirse opcionalmente; si no se incluye, se rellenará por defecto.
Así, la construcción de la tabla sería la siguiente:
df1 = pd.DataFrame(data = [elemento1, # Notar que ingresamos un objeto de tipo lista, dentro de otra lista
elemento2,
elemento3,
["Juana", 24, "Argentina"]], # Además se pueden agregar otras listas sin haberlas declarado antes
columns = ["Nombre", "Edad", "Pais"]) # Ingresamos en una lista los nombres de las columnas
print(df1) Nombre Edad Pais
0 Johny 40 USA
1 Alan 29 Perú
2 Jorge 20 None
3 Juana 24 ArgentinaNote que elemento3, al no poseer datos para “País de procedencia”, Pandas rellena ese dato faltante en el DataFrame con un None.
Ingresar datos tabulares
Existen diferentes tipos de datos almacenados como texto en archivos tabulares. Es importante destacar que, en muchas ocasiones, los datos en Ciencias de la Tierra vienen en un formato de texto no delimitado, como el ASCII (.asc). Sin embargo, Pandas permite crear DataFrames a partir de archivos de texto, y ofrece diversas funciones según el tipo de archivo con el que se esté trabajando.
Para cargar un archivo separado por comas (.csv), se utiliza la función read_csv(), cuya sintaxis es la siguiente:
read_csv(): Da inicio a la funciónfilepath_or_buffer =: String que acepta la ruta (Path) de un archivo con extensión.csvo un enlace que contenga este tipo de archivo.sep =: Símbolo que separa los datos en el archivo. Por defecto, es una coma,(como sugiere el nombre del archivo), pero puede variar según el separador del archivo (ej., punto y coma [;], espacio [], tabulación [\t], entre otros).decimal =: Para especificar qué carácter debe ser interpretado como el separador decimal en los datos numéricos. Por defecto, Pandas asume que el separador decimal es un punto (.), como es común en muchos países, pero en algunos lugares, como en gran parte de Europa y América Latina, el separador decimal es una coma (,). Si tienes un archivo donde los números decimales están separados por comas, puedes indicarle que interprete la coma como separador decimal con el parámetrodecimal = ','. En este caso, los valores como “3,14” serán interpretados como3.14por Pandas.
Ahora cargaremos un archivo .csv que contiene la precipitación mensual en mm de un año, junto con la estación del año a la que pertenece:
precip_prom_mens = pd.read_csv(filepath_or_buffer = 'https://github.com/Aloniss/datosGeoPython2024/raw/refs/heads/main/08-01-precip_mes_tempo.csv', # URL de los datos
sep=',', # el separador de los datos
decimal='.') # separador decimal
precip_prom_mens| meses | precip | temporada | |
|---|---|---|---|
| 0 | Ene | 0.70 | Invierno |
| 1 | Feb | 0.75 | Invierno |
| 2 | Mar | 1.85 | Primavera |
| 3 | Abr | 2.93 | Primavera |
| 4 | May | 3.05 | Primavera |
| 5 | Jun | 2.02 | Verano |
| 6 | Jul | 1.93 | Verano |
| 7 | Ago | 1.62 | Verano |
| 8 | Sep | 1.84 | Otonio |
| 9 | Oct | 1.31 | Otonio |
| 10 | Nov | 1.39 | Otonio |
| 11 | Dic | 0.84 | Invierno |
Características de un DataFrame
Existen variados métodos para poder visualizar las características de un DataFrame:
.info(): Imprime un resumen de información relevante de la tabla.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12 entries, 0 to 11
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 meses 12 non-null object
1 precip 12 non-null float64
2 temporada 12 non-null object
dtypes: float64(1), object(2)
memory usage: 416.0+ bytesEn este caso se puede observar la cantidad de columnas (tres), el tipo de dato (dos object y un float64), las filas (doce), entre otros.
.shape: Retorna una tupla representando las dimensiones de unDataFrame.
Con esto nos damos cuenta que nuestra tabla tiene 12 filas y 3 columnas.
.size: Devuelve la cantidad de elementos que se encuentran dentro de la tabla.
Como el DataFrame tiene 3 columnas y 12 filas, los elementos presentes son 36.
.columns: Entrega los nombres de las columnas de la tabla.
.index: Retorna el índice (o nombre de las filas) de unDataFrame.
Note que, al no explicitar el índice (index =) dentro de read_csv() anteriormente, Pandas ha asignado uno a través de una secuencia que comienza en 0 y termina en 12, avanzando de uno en uno.
.head(n): Retorna las primerasnfilas. Esto es particularmente útil para no mostrar una gran cantidad de datos.
| meses | precip | temporada | |
|---|---|---|---|
| 0 | Ene | 0.70 | Invierno |
| 1 | Feb | 0.75 | Invierno |
| 2 | Mar | 1.85 | Primavera |
| 3 | Abr | 2.93 | Primavera |
.tail(n): Similar a.head, muestra las últimasnfilas.
| meses | precip | temporada | |
|---|---|---|---|
| 8 | Sep | 1.84 | Otonio |
| 9 | Oct | 1.31 | Otonio |
| 10 | Nov | 1.39 | Otonio |
| 11 | Dic | 0.84 | Invierno |
Acceder a elementos dentro de un DataFrame
En Pandas existen varias formas de acceder a los elementos de un DataFrame. Si se desea acceder a una columna específica, se puede utilizar la siguiente notación:
df["columna"]Donde df es el DataFrame en el que buscar y "columna" es la columna de interés.
0 Invierno
1 Invierno
2 Primavera
3 Primavera
4 Primavera
5 Verano
6 Verano
7 Verano
8 Otonio
9 Otonio
10 Otonio
11 Invierno
Name: temporada, dtype: objectOtra forma de acceder a los elementos al interior de un DataFrame es usando .loc e .iloc.
.loc(): Acceso por etiqueta (label-based)
Este método selecciona los datos basándose en las etiquetas de los índices y columnas. Utiliza los nombres de las filas y columnas, y puede aceptar una lista, rango o condición booleana.
Veamos un ejemplo:
.iloc(): Acceso por posición (integer-based)
Editar un DataFrame
Muchas veces es necesario, además de acceder a los elementos de un DataFrame, realizar cambios en los mismos, para esto existen una serie de funciones que se pueden aplicar:
.rename(index =, columns =, inplace =, axis =, error =): permite renombrar las etiquetas de las filas (índices) o columnas de unDataFrameoSerie. Es útil para cambiar los nombres de las etiquetas, ya sea de las columnas o de los índices. Sin embargo, no modifica elDataFrameoriginal a menos que se utilice el parámetroinplace = True.
Parámetros principales:
index: Un diccionario o función que se utiliza para renombrar los índices (filas). Las claves son los nombres actuales, y los valores son los nuevos nombres.- Ejemplo:
df.rename(index= {'nombre_antiguo': 'nombre_nuevo'})
- Ejemplo:
columns: Un diccionario o función para renombrar las columnas. Igual que el parámetroindex, las claves son los nombres actuales de las columnas, y los valores son los nuevos nombres.- Ejemplo:
df.rename(columns={'A': 'Nuevo_A'})
- Ejemplo:
inplace: Un valor booleano. Si se establece enTrue, modifica elDataFrameoriginal en lugar de devolver una copia modificada. El valor predeterminado esFalse.- Ejemplo:
df.rename(columns={'A': 'Nuevo_A'}, inplace=True)
- Ejemplo:
axis: Permite especificar si quieres renombrar los índices (axis=0) o las columnas (axis=1). En lugar de usarindexocolumns, puedes utilizar este parámetro para mayor flexibilidad.- Ejemplo:
df.rename({'A': 'Nuevo_A'}, axis = 1)(renombrar columnas)
- Ejemplo:
errors: Por defecto, está configurado en ‘ignore’, lo que significa que si alguna etiqueta que intentas renombrar no existe, Pandas simplemente la ignorará y no lanzará un error.- Ejemplo: Si intentas renombrar una columna inexistente, Pandas no detendrá la ejecución por el error:
- Ejemplo:
df.rename(columns = {'C': 'New_C'}, errors = 'ignore')
Para agregar elementos a un DataFrame, es posible hacerlo de varias maneras, aunque acá solo mostraremos dos:
- Asignación directa:
Puedes asignar una nueva columna utilizando el nombre de la columna entre corchetes y los valores que deseas agregar.
Para realizar esta inserción, la lista debe tener la misma longitud que la cantidad de observaciones de la tabla.
- Agregar una columna usando
assign():
El método assign() permite agregar una o varias columnas y devuelve un nuevo DataFrame sin modificar el original, a menos que se reasigne el resultado.
| meses | precip | temporada | temp_prom | temp_max | |
|---|---|---|---|---|---|
| 0 | Ene | 0.70 | Invierno | 5.0 | 11 |
| 1 | Feb | 0.75 | Invierno | 6.2 | 12 |
| 2 | Mar | 1.85 | Primavera | 10.1 | 15 |
| 3 | Abr | 2.93 | Primavera | 12.3 | 17 |
| 4 | May | 3.05 | Primavera | 15.0 | 28 |
| 5 | Jun | 2.02 | Verano | 18.5 | 26 |
| 6 | Jul | 1.93 | Verano | 20.1 | 25 |
| 7 | Ago | 1.62 | Verano | 19.7 | 28 |
| 8 | Sep | 1.84 | Otonio | 16.5 | 19 |
| 9 | Oct | 1.31 | Otonio | 12.4 | 16 |
| 10 | Nov | 1.39 | Otonio | 8.7 | 13 |
| 11 | Dic | 0.84 | Invierno | 6.0 | 10 |
Para eliminar una columna en un DataFrame de Pandas, puedes usar varios métodos.
- Usando
.drop()
El método .drop() permite eliminar una columna o varias columnas del DataFrame especificando el nombre de la columna y el parámetro axis=1 para indicar que se debe eliminar una columna (las filas se eliminan con axis=0).
Los parámetros son:
'NombreColumna': Especifica el nombre de la columna que deseas eliminar.axis=1: Indica que se eliminará una columna (para eliminar filas, se usaríaaxis=0).inplace=True(opcional): Si deseas que elDataFrameoriginal se modifique directamente sin necesidad de reasignar, puedes usar este parámetro.
| meses | precip | temp_prom | |
|---|---|---|---|
| 0 | Ene | 0.70 | 5.0 |
| 1 | Feb | 0.75 | 6.2 |
| 2 | Mar | 1.85 | 10.1 |
| 3 | Abr | 2.93 | 12.3 |
| 4 | May | 3.05 | 15.0 |
| 5 | Jun | 2.02 | 18.5 |
| 6 | Jul | 1.93 | 20.1 |
| 7 | Ago | 1.62 | 19.7 |
| 8 | Sep | 1.84 | 16.5 |
| 9 | Oct | 1.31 | 12.4 |
| 10 | Nov | 1.39 | 8.7 |
| 11 | Dic | 0.84 | 6.0 |
- Usando
.pop()
El método .pop() en también se puede utilizar para eliminar una columna de un DataFrame, pero a diferencia de .drop(), .pop() elimina la columna y además la devuelve como una `Serie. Esto es útil cuando quieres eliminar una columna pero también necesitas trabajar con los datos de esa columna de manera separada.
0 Invierno
1 Invierno
2 Primavera
3 Primavera
4 Primavera
5 Verano
6 Verano
7 Verano
8 Otonio
9 Otonio
10 Otonio
11 Invierno
Name: temporada, dtype: object| meses | precip | temp_prom | |
|---|---|---|---|
| 0 | Ene | 0.70 | 5.0 |
| 1 | Feb | 0.75 | 6.2 |
| 2 | Mar | 1.85 | 10.1 |
| 3 | Abr | 2.93 | 12.3 |
| 4 | May | 3.05 | 15.0 |
| 5 | Jun | 2.02 | 18.5 |
| 6 | Jul | 1.93 | 20.1 |
| 7 | Ago | 1.62 | 19.7 |
| 8 | Sep | 1.84 | 16.5 |
| 9 | Oct | 1.31 | 12.4 |
| 10 | Nov | 1.39 | 8.7 |
| 11 | Dic | 0.84 | 6.0 |
Asimismo, para agregar una fila en un DataFrame puedes usar varios métodos.
- Usar
.loc[]para agregar una fila
Con .loc[], puedes asignar una nueva fila proporcionando un índice y los valores correspondientes. Esta es una forma directa, especialmente útil cuando conoces el índice de la fila que deseas agregar.
| meses | precip | temp_prom | |
|---|---|---|---|
| 0 | Ene | 0.70 | 5.0 |
| 1 | Feb | 0.75 | 6.2 |
| 2 | Mar | 1.85 | 10.1 |
| 3 | Abr | 2.93 | 12.3 |
| 4 | May | 3.05 | 15.0 |
| 5 | Jun | 2.02 | 18.5 |
| 6 | Jul | 1.93 | 20.1 |
| 7 | Ago | 1.62 | 19.7 |
| 8 | Sep | 1.84 | 16.5 |
| 9 | Oct | 1.31 | 12.4 |
| 10 | Nov | 1.39 | 8.7 |
| 11 | Dic | 0.84 | 6.0 |
| 12 | Ene | 0.90 | 10.0 |
- Usar
.concat()para unirDataFramesoSeries
El método .concat() se utiliza para unir o concatenar objetos como DataFrames o Series a lo largo de un eje, ya sea filas (por defecto) o columnas. Es una herramienta muy flexible para combinar datos y permite realizar concatenaciones horizontales o verticales.
pd.concat(objs,
axis = 0,
join ='outer',
ignore_index= False,
keys = None,
...)Los parámetros principales son:
objs: Una lista deDataFramesoSeriesque se desea concatenar.- Ejemplo:
objs=[df1, df2]
- Ejemplo:
axis: Especifica a lo largo de qué eje concatenar los objetos.axis=0(por defecto): Une a lo largo de las filas (apila).axis=1: Une a lo largo de las columnas (lado a lado).
join: Determina cómo se deben manejar los índices en losDataFrames/Series.'outer'(por defecto): Realiza una unión externa, manteniendo todos los índices.'inner': Realiza una unión interna, solo conservando los índices comunes.
ignore_index: Si esTrue, no se conservan los índices originales y se reasignan como si fueran consecutivos. Útil si los índices son irrelevantes.- Ejemplo:
ignore_index=True.
- Ejemplo:
keys: Se utiliza para crear una jerarquía de niveles en unDataFrameconcatenado, útil para combinar múltiplesDataFramesy luego acceder a ellos por clave.
df3 = pd.DataFrame({
'Columna_A': [1, 2, 3],
'Columna_B': [4, 5, 6]
})
df4 = pd.DataFrame({
'Columna_A': [7, 8, 9],
'Columna_B': [10, 11, 12]
})
df3| Columna_A | Columna_B | |
|---|---|---|
| 0 | 1 | 4 |
| 1 | 2 | 5 |
| 2 | 3 | 6 |
# Concatenar a lo largo de las filas
df_concat_filas = pd.concat([df3, df4], axis=0)
df_concat_filas| Columna_A | Columna_B | |
|---|---|---|
| 0 | 1 | 4 |
| 1 | 2 | 5 |
| 2 | 3 | 6 |
| 0 | 7 | 10 |
| 1 | 8 | 11 |
| 2 | 9 | 12 |
# Concatenar a lo largo de las columnas
df_concat_columnas = pd.concat([df3, df4], axis=1)
df_concat_columnas| Columna_A | Columna_B | Columna_A | Columna_B | |
|---|---|---|---|---|
| 0 | 1 | 4 | 7 | 10 |
| 1 | 2 | 5 | 8 | 11 |
| 2 | 3 | 6 | 9 | 12 |
# Concatenar eliminando los índices originales
df_concat_sin_index = pd.concat([df3, df4], ignore_index=True)
df_concat_sin_index| Columna_A | Columna_B | |
|---|---|---|
| 0 | 1 | 4 |
| 1 | 2 | 5 |
| 2 | 3 | 6 |
| 3 | 7 | 10 |
| 4 | 8 | 11 |
| 5 | 9 | 12 |
Puede encontrar más información visitando la documentación oficial de Pandas.
Limpiando datos tabulares de texto para abrirlos en Python
No todos los archivos de texto se ven tan simples como los que se mostraron arriba. Muchos archivos tienen varias líneas en las cabeceras que aparecen sobre los datos y que nos pueden proporcionar información de utilidad sobre los mismos datos. Este tipo de información es conocida como los metadatos. Por otra parte, a menudo existen datos faltantes entre los datos que se colectaron. Estos valores perdidos se pueden identificar usando un valor específico que usualmente está identificado en el metadato.
# Explorar los valores de los datos
# Abrir los datos de temperatura de Valdivia, Chile
vald_prec_url = "https://github.com/Aloniss/datosGeoPython2024/raw/refs/heads/main/08-02-valdi_precip_anual.csv"
vald_prec = pd.read_csv(vald_prec_url)
vald_prec.info()
vald_prec<class 'pandas.core.frame.DataFrame'>
RangeIndex: 74 entries, 0 to 73
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 # Valdivia 74 non-null object
1 Chile Enero-Diciembre Precipitación Acumulada Promedio 72 non-null object
dtypes: object(2)
memory usage: 1.3+ KB| # Valdivia | Chile Enero-Diciembre Precipitación Acumulada Promedio | |
|---|---|---|
| 0 | # Unidades: milimetros | NaN |
| 1 | # Datos-Faltantes: -99 | NaN |
| 2 | Fecha | Valor |
| 3 | 195012 | 2507.3 |
| 4 | 195112 | 3427.8 |
| ... | ... | ... |
| 69 | 201912 | 1071.3 |
| 70 | 202012 | 1400.9 |
| 71 | 202112 | 949 |
| 72 | 202212 | 1367.8 |
| 73 | 202312 | 1468.6 |
74 rows × 2 columns
Tenga en cuenta que los datos mostrados arriba contienen unas filas extras de información. Esta información es importante para el entendimiento de los datos.
Datos-Faltantes: -99. Este representa un valor no data. Es un dato perdido que podría ocurrir si el sensor dejó de operar o la medición no es almacenada. Será necesario remover estos no-data.
Unidades: milimetros. Es importante primero entender cuáles son las unidades de los datos antes de intentar interpretar que están mostrando.
Vamos a ver cómo podemos remover las primeras filas de datos del archivo que no contienen valores, es decir, remover las filas que contienen a los metadatos.
Parámetros en las funciones de Python
Un parámetro se refiere a una opción que se puede especificar cuando se ejecuta una función en Python. Se puede ajustar los parámetros asociados cuando se importan, grafican o procesan los datos para limpiarlos de entradas no deseadas. Más abajo usaremos:
Skiprows =: para decirle a Python que se salte las 3 primeras filas de los datos.na_values =: para decirle a Python que reasigne cualquier dato perdido a un valorNA.
En general NA se refiere a datos perdidos. Cuando se especifica un valor como NA (NaN o Not a Number), este no será incluido en los gráficos o en las operaciones matemáticas.
# Abrir los datos de Valdivia, pero ignorando las primeras 3 filas y asignando como NA a los no-data
vald_prec = pd.read_csv(vald_prec_url,
skiprows = 3,
na_values = -99)
# Mostrando solo las primeras 5 filas de los datos
vald_prec.head()| Fecha | Valor | |
|---|---|---|
| 0 | 195012 | 2507.3 |
| 1 | 195112 | 3427.8 |
| 2 | 195312 | 2940.0 |
| 3 | 195412 | 2050.8 |
| 4 | 195512 | 1240.5 |
8.3 Graficando Datos Tabulares
Para facilitar el análisis de datos o su comunicación, los gráficos pueden ser extremadamente útiles, ya que permiten identificar patrones, tendencias y anomalías, además de hacer los resultados más accesibles y comprensibles para el público. En Python, una de las bibliotecas especializadas en la creación de gráficos es Matplotlib.
La librería Matplotlib es una de las más utilizadas en Python para la creación de gráficos y visualizaciones. Proporciona una interfaz flexible para crear gráficos desde simples hasta altamente personalizados. Su submódulo más popular es pyplot, que permite crear gráficos de manera similar a Matlab.
Estructura Básica de Matplotlib
En Matplotlib, la visualización se compone de varios elementos clave:
Figure(Figura): Es el contenedor general de todos los elementos gráficos. Cada gráfico reside dentro de una Figura, y se puede tener varias figuras abiertas simultáneamente. Una figura puede contener múltiples ejes (subgráficos).Axes(Ejes): Son las áreas donde se dibuja uno o varios gráficos dentro de una figura. Un solo gráfico o visualización ocupa un conjunto de ejes. En los ejes se define el sistema de coordenadas, las escalas de los ejesXeY, y los elementos gráficos.Axis(Eje): Se refiere a los ejes individuales (eje X y eje Y). Cada eje puede tener etiquetas, límites, marcas y escala.Artist(Artistas): Todo lo que aparece en la figura es un “artista”, incluyendo las figuras, los ejes, las leyendas, las etiquetas de los ejes, etc. Todos estos objetos pueden ser modificados para personalizar el gráfico.Subplot(Subgráfico): Es un espacio dividido dentro de una figura que permite colocar varios gráficos en diferentes disposiciones. Utiliza un sistema de cuadrículas para dividir la figura en subgráficos.
La siguiente imagen contiene las partes que componen a un gráfico en Matplotlib.
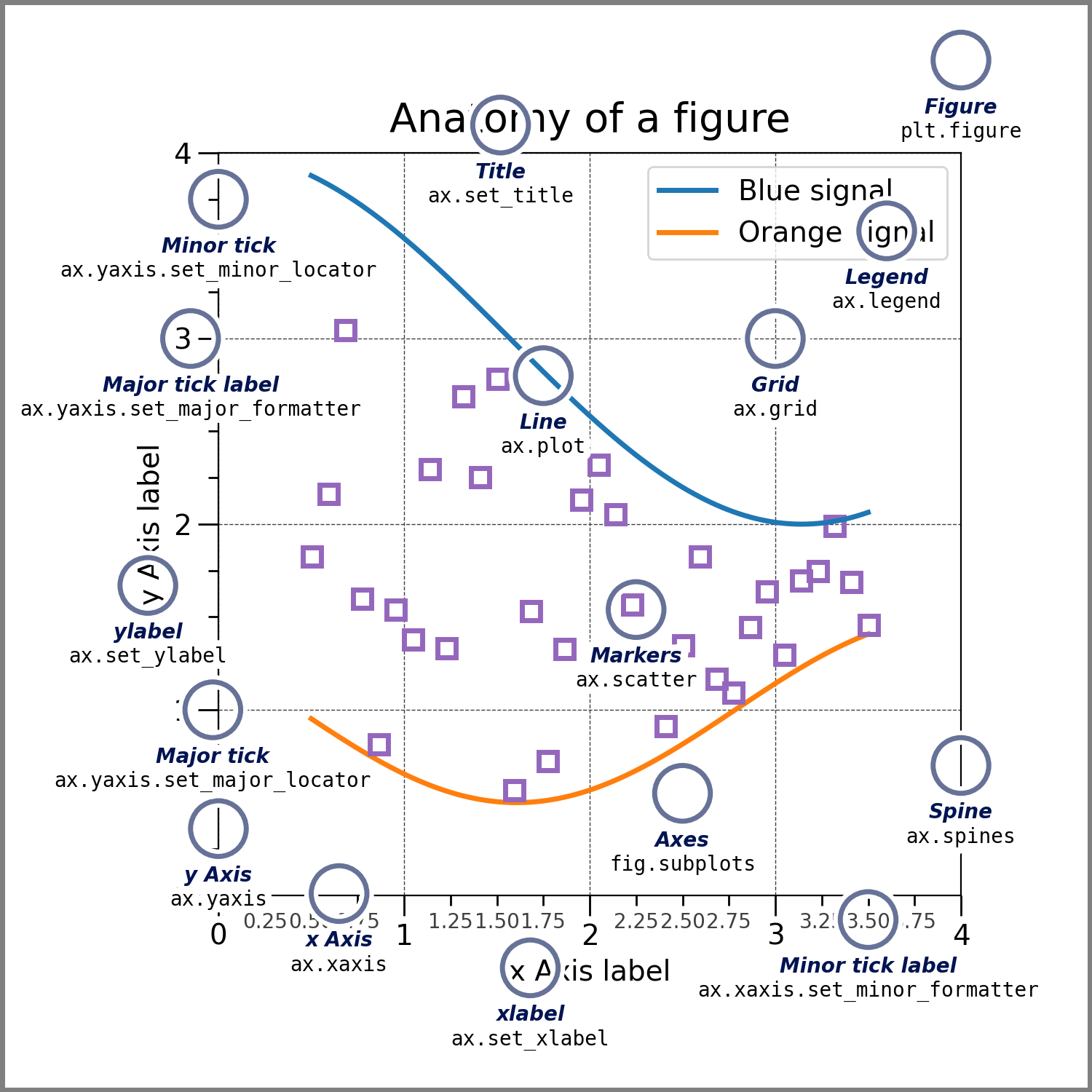
Creación de una Figura
- Importar el módulo
pyplotdesde la librería, generalmente abreviado comoplt:
- Hay que llamar a la función
subplots()para inicializar la figura. Este comando tiene varios parámetros:
nrowsyncols: Define la cantidad de gráficos que habrá en la figura (Figure). Por defecto, ambos valen 1 se graficará un solo gráfico).sharex, sharey: De haber más de un gráfico, se debe ingresar un booleano para compartir los mismos valores en los ejes X e Y.
La función subplots() devuelve dos elementos: una Figure (fig) y Axes, que puede ser un solo objeto ax si se crea un solo gráfico, o un array con varios ejes si hay múltiples gráficos.
Por ejemplo, se creará una figura con un gráfico:
Note que simplemente se muestra la figura sin ningún tipo de detalle.
En el caso de que se quieran plotear dos gráficos a la vez, se deben definir la cantidad de filas y de columnas:
Aquí, ax es un array que representa las áreas de ambos gráficos en un único elemento:
Para gestionar cada gráfico por separado, se puede crear directamente un array de ejes:
Donde ax1 es el área de dibujo especificada para un gráfico:
- Agregar elementos visuales como títulos, leyendas y grillas. Estas opciones se aplican también al objeto
Axes(ax):
ax.legend(): Para agregar una leyenda.ax.grid(): Para dibujar una rejillaax.set: Distintas funciones para cambiar el aspecto de los ejes (tal comoxlabelyylabelpara cambiar las etiquetas de los ejes de un gráfico, por ejemplo).
- Integración con
DataFrames. Para gráficos basados en Pandas, se utiliza la función.plot(), que tiene la siguiente sintaxis:
.plot(kind = tipo, x = columnax, y = columnay, ax = ejes)Donde kind indica el tipo de gráfico (líneas, puntos, histograma, etc.), x y y representan los ejes, y ax define los ejes donde se dibujará el gráfico.
- Por último, para mostrar el gráfico se debe ocupar el comando
.show().
Por ejemplo, graficamos el DataFrame correspondiente a la precipitación en Valdivia desde 1950 en un gráfico de líneas:
# Inicializar figura y ejes
f, ax = plt.subplots()
# Graficar el DataFrame
vald_prec.plot(kind = "line", # Tipo de gráfico
x = "Fecha", # Eje X
y = "Valor", # Eje Y
title = "Precipitación Valdivia", # Título
ax = ax) # Asignar el área del gráfico
# Personalizar etiquetas
ax.set(xlabel = 'Fecha', # Etiqueta en el eje X
ylabel = 'Valor') # Etiqueta en el eje Y
# Mostrar gráfico
plt.show()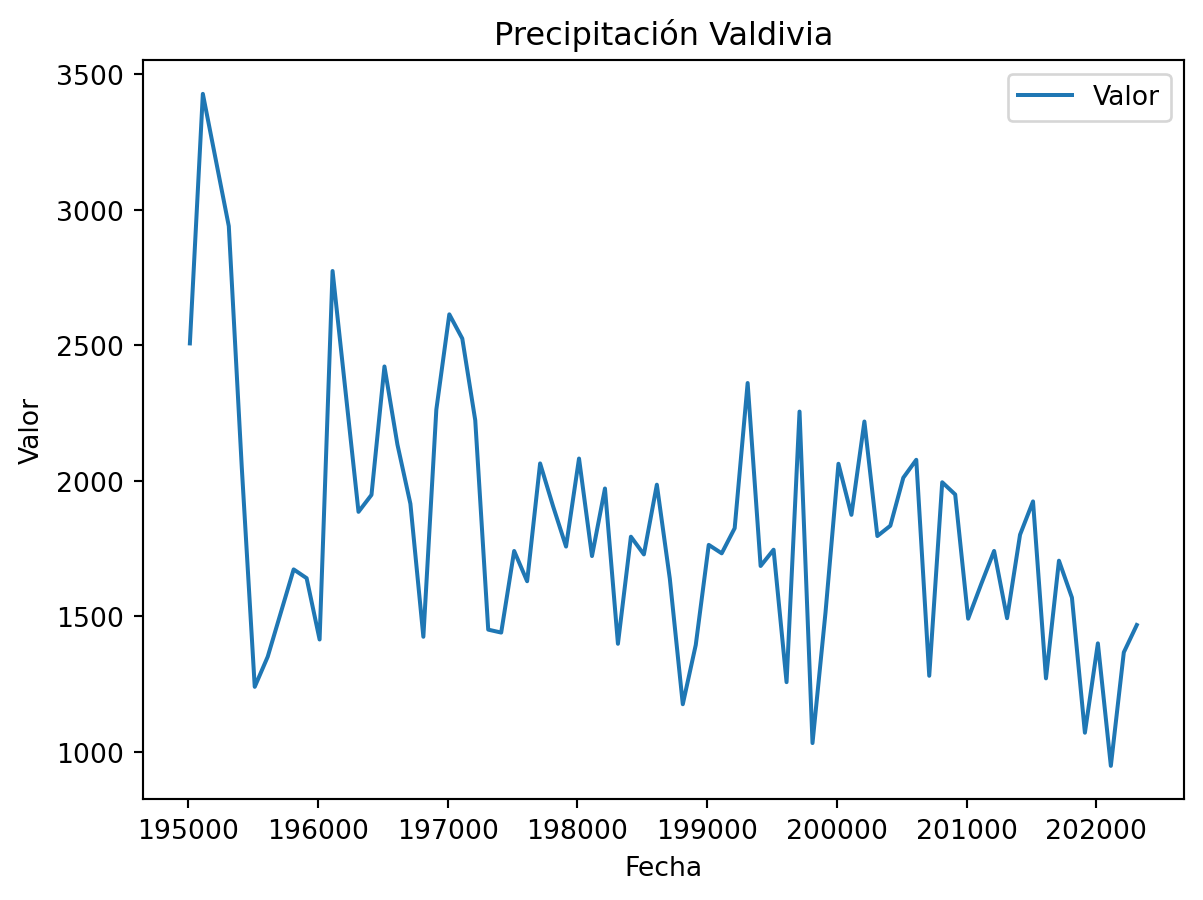
En este otro ejemplo, graficamos las precipitaciones como puntos y las temperaturas como barras usando el DataFrame precip_prom_mens:
# Inicializar figura con dos gráficos
fig, (ax1, ax2) = plt.subplots(ncols=2,
nrows=1)
# Graficar precipitaciones como puntos
precip_prom_mens.plot(ax = ax1,
kind = "scatter",
x = "meses",
y = "precip",
title = "Precipitación (mm) para 1 año")
# Graficar temperaturas como barras
precip_prom_mens.plot(ax = ax2,
kind = "bar",
x = "meses",
y = "temp_prom",
title = "Temperatura (°C) para 1 año")
# Etiquetas para ambos gráficos
ax1.set(xlabel = 'Mes',
ylabel = 'Precipitación (mm)')
ax2.set(xlabel = 'Mes',
ylabel = 'Temperatura (°C)')
# Mostrar gráficos
plt.show()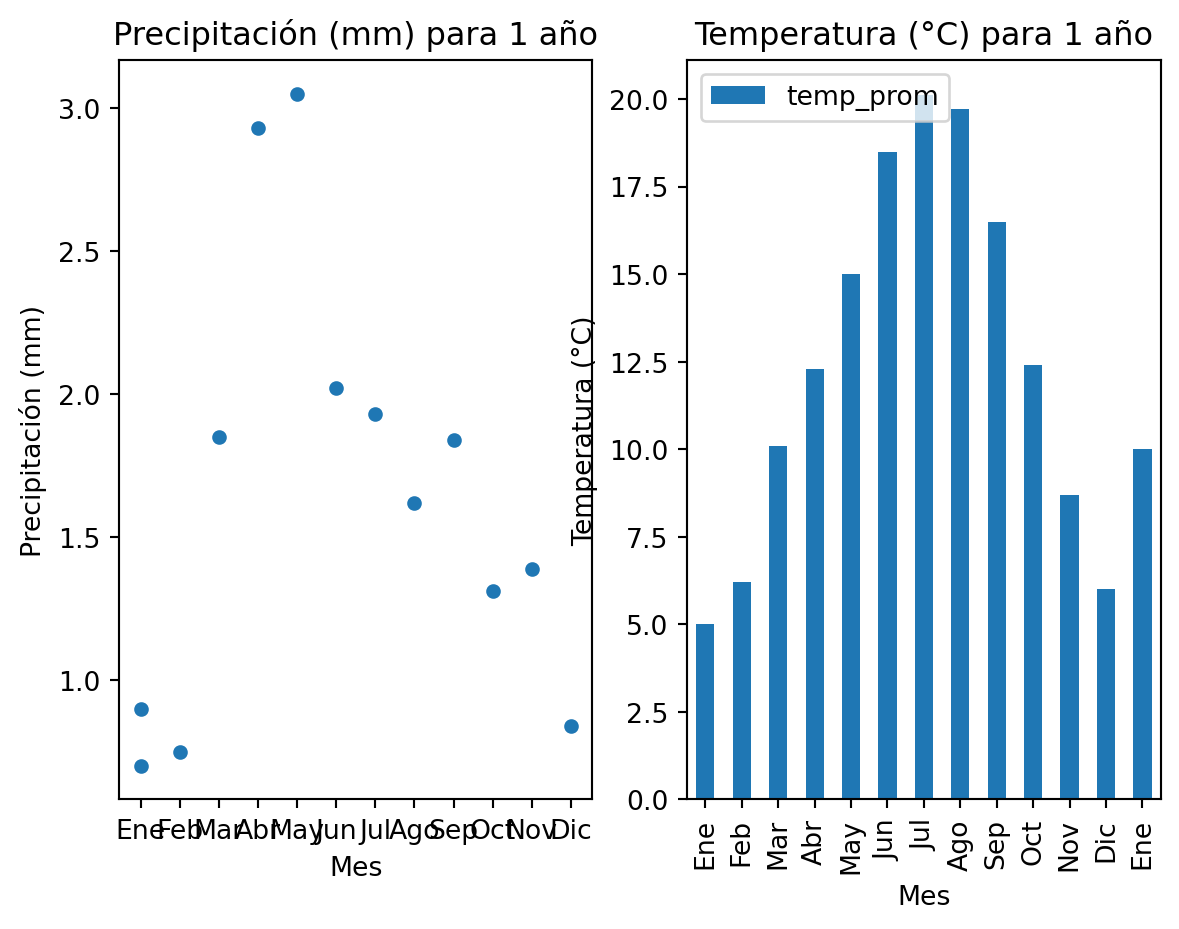
Si desea más información sobre esta librería, puede revisar el siguiente link, o visitar la documentación oficial de Matplotlib.
Ayudantía
Disponible la ayudantía que contiene los ejercicios revisados en la clase: