9 Formato de datos espaciales - Vector
En este capítulo vamos a aprender acerca de uno de principales modelos de representación que son útiles en las Ciencias de los Tierra, el modelo vectorial. Además, se aprenderá como abrir, explorar y plotear datos vectoriales en distintos formatos usando el paquete Geopandas de Python.
9.1 Sobre los datos vectoriales espaciales
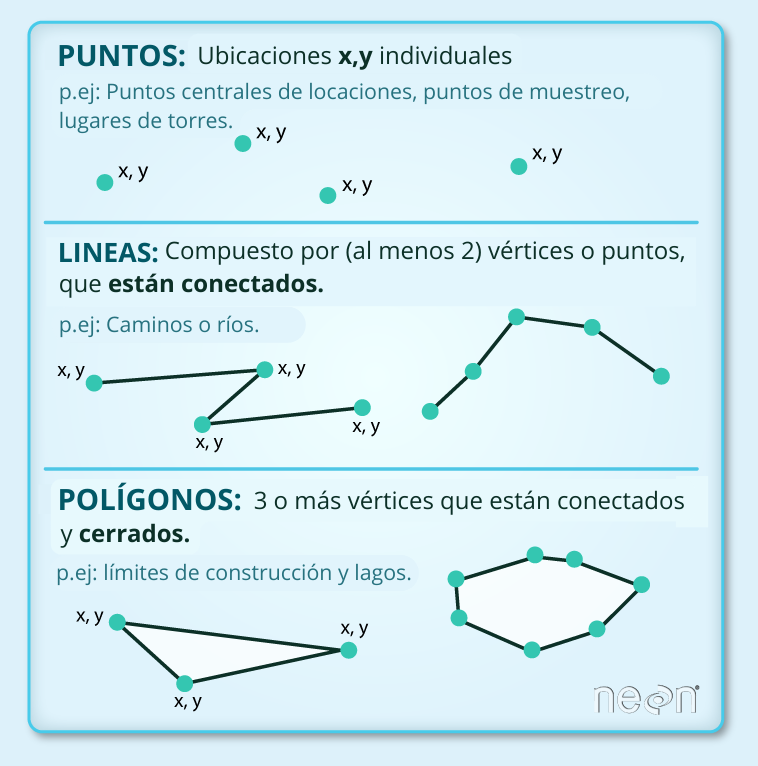
Los datos vectoriales están compuestos de posiciones geométricas discretas (valores x,y), conocidos como vértices, que definen la forma del objeto espacial. La organización de los vértices determina el tipo de vector con el que se está trabajando. Existen tres tipos de datos vectoriales:
Puntos: cada punto individual es definido por una única coordenada x,y. Como ejemplos de esto se tienen: posiciones de muestreo, posiciones de árboles individuales, o posiciones de las parcelas.
Líneas: las líneas están compuestas de muchos (al menos 2) vértices, o puntos que están conectados. Por ejemplo, un camino o un curso de agua pueden estar representados por una línea. Esta línea está compuesta de una serie de segmentos, cada curva en el camino o en el curso de agua, representa un vértice que está definido por una posición
x,y.Polígonos: consiste de 3 o más vértices que están conectados y cerrados. De esta forma, los contornos de los elementos en la naturaleza como, lagos, océanos, municipios o regiones a menudo son representados por polígonos.
Introducción al formato de archivos shapefile para almacenar puntos, líneas y polígonos
Los datos geoespaciales que están en formato vectorial, a menudo son almacenados en un formato de archivo shapefile (.shp). Debido a que la estructura de los puntos, líneas y polígonos son diferentes, cada archivo shapefile solo puede contener un tipo de vector (puntos, líneas o polígonos). No es posible encontrar una mezcla de objetos de puntos, líneas o polígonos en un único archivo shapefile. Los objetos son almacenados en un shapefile a menudo tienen asociado un grupo de atributos que describen los datos. Por ejemplo, una línea shapefile que contiene las posiciones de un estero, puede también tener asociada un nombre del estero, una jerarquía, y otra información relevante de ese objeto.
Archivos GeoJSON y otros formatos vectoriales
El shapefile no es la única forma de que un dato vectorial sea almacenado. Los datos geoespaciales también pueden ser entregados en el formato GeoJSON, o incluso en un formato tabular donde la información espacial se encuentra contenida en columnas.
Podemos ejercitar el abrir estos formatos descargando el siguiente archivo .geojson. Estos datos corresponden a una base de datos histórica de cicatrices de fuego en Chile (propiedad del (CR)2 y disponible en el siguiente link.)
9.2 Como leer archivos vectoriales
En Python, una de las formas de leer archivos vectoriales es a través del paquete Geopandas. Como su nombre lo indica, esta librería extiende el paquete Pandas (visto en la sección anterior) añadiendo soporte para el componente geoespacial. La estructura central de los datos es un geopandas.GeoDataFrame, que a su vez está compuesto por geopandas.GeoSeries. Esta estructura es similar a un DataFrame tradicional, pero en este caso contiene una columna con las geometrías de cada fila, como se muestra en la siguiente imagen:
geopandas.GeoDataFrame.
En un GeoDataFrame, la columna geometry almacena la información espacial. Esta columna contiene los límites (líneas que definen las formas en los datos), permitiendo representar puntos, líneas o polígonos. También se almacenan atributos espaciales como los sistemas de referencia de coordenadas y la extensión espacial.
Para utilizar esta librería, primero debemos importarla en nuestro Jupyter Notebook. Comúnmente se abrevia como gpd:
En este caso, la declaración os.environ['USE_PYGEOS'] = '0' se utiliza porque GeoPandas emplea el paquete Shapely para gestionar las geometrías. Sin embargo, GeoPandas también tiene soporte para la librería PyGEOS, por lo que indicamos que en nuestro entorno no se use esta última.
Para importar archivos vectoriales, como el .geojson descargado anteriormente, se utiliza la función `.read_file()``, la cual tiene varios parámetros importantes. Algunos de ellos son:
filename =: La ruta del archivo que queremos leer.rows =: Número de filas a leer, opcional.
El siguiente ejemplo lee los datos de forma tabular:
| FireID | FireSeason | RegionCode | Region_CON | FireName_C | Area_CONAF | IgnitionDa | ControlDat | Latitude_[ | Longitude_ | ... | TotalArea_ | AreaUnchS_ | AreaLowS_[ | AreaModS_[ | AreaHighS_ | FireScarPo | SeverityPo | OverlapIDs | Observatio | geometry | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ID10000 | 1986.0 | CL-BI | BioBio | RAPELCO | 51.0 | 1986-01-04 | 1986-01-04 | -37.6710 | -72.3978 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | None | None | POINT (-72.3978 -37.671) |
| 1 | ID100000 | 2003.0 | CL-ML | Maule | MAITENHUAPI | 50.0 | 2003-02-09 | 2003-02-09 | -35.3283 | -71.5799 | ... | 4.278272e+05 | 0.0 | 0.0 | 178748.092346 | 2.490791e+05 | 1.0 | 57.0 | None | None | POINT (-71.5799 -35.3283) |
| 2 | ID10002 | 1986.0 | CL-BI | BioBio | LAs chilcas | 87.0 | 1986-02-03 | 1986-02-03 | -36.6711 | -71.9708 | ... | 3.227681e+06 | 0.0 | 0.0 | 710373.072388 | 2.517308e+06 | 16.0 | 423.0 | None | The ignition point is located in the current C... | POINT (-71.9708 -36.6711) |
| 3 | ID100027 | 2003.0 | CL-ML | Maule | LAS CATALINAS II | 80.0 | 2003-02-15 | 2003-02-16 | -35.5755 | -72.1725 | ... | 1.155078e+06 | 0.0 | 0.0 | 539904.116699 | 6.151739e+05 | 6.0 | 122.0 | None | None | POINT (-72.1725 -35.5755) |
| 4 | ID10003 | 1986.0 | CL-BI | BioBio | NAHUELTORO 1 | 53.0 | 1986-02-06 | 1986-02-06 | -36.4938 | -71.8524 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | None | None | POINT (-71.8524 -36.4938) |
5 rows × 36 columns
Además, al igual que Pandas, GeoPandas se integra fácilmente con Matplotlib, lo que nos permite dibujar los datos:
import matplotlib.pyplot as plt
f, ax = plt.subplots(figsize = (7, 7)) # Definimos el tamaño de la figura
df.plot(ax = ax, # Definimos el espacio para trazar el gráfico
color = "r") # Asignamos color rojo
plt.show()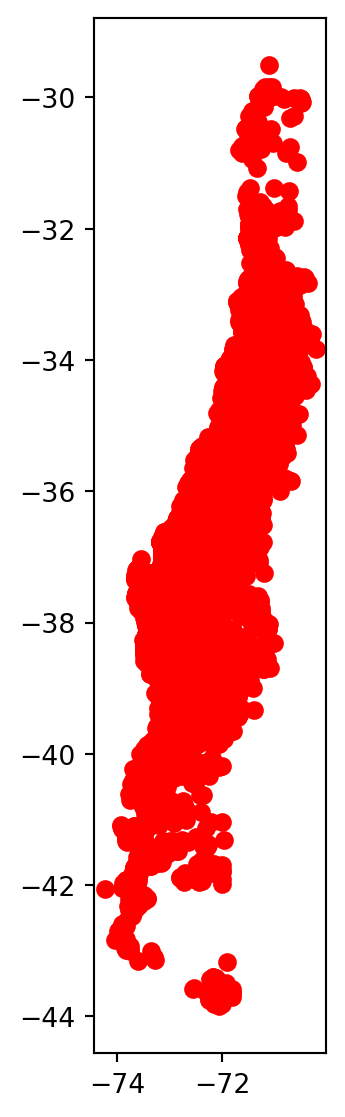
Puedes encontrar más información sobre archivos .geojson en las siguientes fuentes:
¿Cuáles datos son almacenados en un formato de vectores espaciales?
Solo por mencionar en una lista que no es exhaustiva:
Datos censales que incluyan los límites municipales.
Caminos, líneas de transmisión, y otras infraestructuras.
Límites políticos-administrativos.
Contornos de edificios, manzanas, bloques.
Cuerpos de agua, sistemas fluviales.
Zonas ecológicas.
Posiciones de pueblos, caseríos, ciudades.
Posiciones de parcelas, medidores de servicios, postaciones.
9.3 Importar datos shapefile en Python usando GeoPandas
Para continuar practicando, cargaremos y graficaremos tanto las fronteras de los países como sus líneas costeras. Para facilitar este proceso, utilizaremos también la librería earthpy, que nos permite descargar datos directamente desde internet.
/usr/share/miniconda/envs/tallerpython/lib/python3.10/site-packages/earthpy/__init__.py:7: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
from pkg_resources import resource_stringRecordatorio: Cuando descargamos datos con el paquete earthpy, se genera un directorio llamado
earth-analyticsen el directorioHOME. Además, si los datos provienen de una URL, se crea un directorio llamadoearthpy-downloads.
# Descarga los borde de los paises
url="http://naciscdn.org/naturalearth/50m/cultural/ne_50m_admin_0_boundary_lines_land.zip"
# Descarga y descomprime dentro de earthpy-downloads
et.data.get_data(url = url)
# Cambia al directorio de trabajo que ya fue creado
os.chdir(os.path.join(et.io.HOME, 'earth-analytics'))
# Crea la ruta hacia el archivo de interés
boundary_path = os.path.join("data", "earthpy-downloads",
"ne_50m_admin_0_boundary_lines_land",
"ne_50m_admin_0_boundary_lines_land.shp")
# Abre el archivo y lee las 5 primeras filas de los datos
boundary = gpd.read_file(boundary_path)
boundary.head()| scalerank | featurecla | name | min_zoom | geometry | |
|---|---|---|---|---|---|
| 0 | 1 | Disputed (please verify) | None | 0.0 | LINESTRING (47.97819 7.99708, 48.12671 8.22219... |
| 1 | 1 | Indefinite (please verify) | None | 0.0 | LINESTRING (47.97819 7.99708, 47.73159 7.75935... |
| 2 | 1 | Disputed (please verify) | None | 0.0 | LINESTRING (34.24528 31.20833, 34.34832 31.292... |
| 3 | 1 | Disputed (please verify) | None | 0.0 | LINESTRING (35.55145 32.39552, 35.48443 32.401... |
| 4 | 1 | Disputed (please verify) | None | 0.0 | LINESTRING (35.10859 33.08367, 35.22331 33.091... |
# Descarga la linea costera
coastlines_url = "http://naciscdn.org/naturalearth/50m/physical/ne_50m_coastline.zip"
# Descarga y descomprime dentro de earthpy-downloads
et.data.get_data(url=coastlines_url)
# Crea la ruta hacia el archivo de interés
coastlines_path = os.path.join("data", "earthpy-downloads",
"ne_50m_coastline",
"ne_50m_coastline.shp")
# Abre el aarchivo y lee las 5 primeras filas de los datos
coastlines = gpd.read_file(coastlines_path)
coastlines.head()| scalerank | featurecla | min_zoom | geometry | |
|---|---|---|---|---|
| 0 | 0 | Coastline | 1.5 | LINESTRING (180 -16.15293, 179.84814 -16.21426... |
| 1 | 0 | Coastline | 4.0 | LINESTRING (177.25752 -17.0542, 177.2874 -17.0... |
| 2 | 0 | Coastline | 4.0 | LINESTRING (127.37266 0.79131, 127.35381 0.847... |
| 3 | 0 | Coastline | 3.0 | LINESTRING (-81.32231 24.68506, -81.42007 24.7... |
| 4 | 0 | Coastline | 4.0 | LINESTRING (-80.79941 24.84629, -80.83887 24.8... |
De forma similar a Pandas, los geoDataFrame pueden ser graficados usando .plot().
# Plotear los datos
f, ax1 = plt.subplots(figsize = (9, 6))
coastlines.plot(ax = ax1)
# Agrega un título al plot
ax1.set(title="Líneas de bordes costeros a escala Global")
plt.show()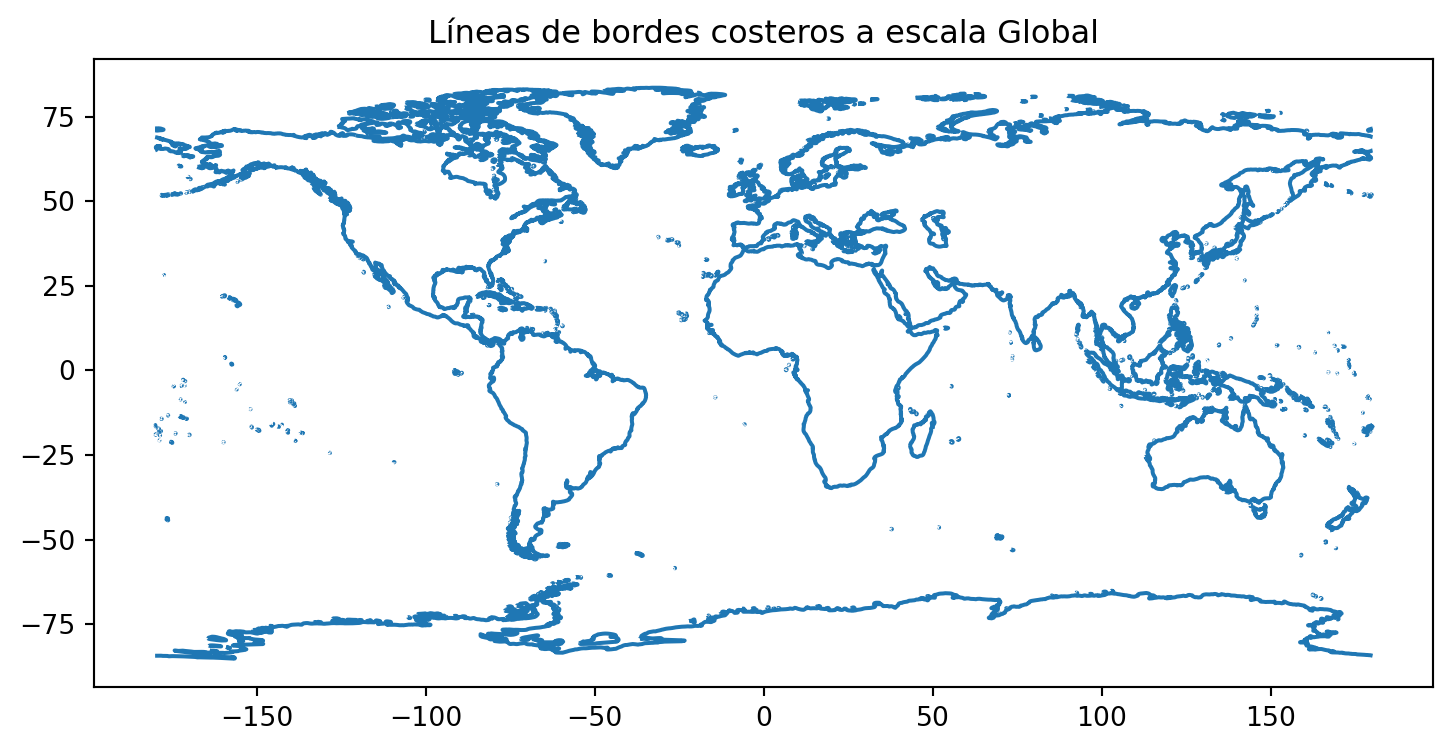
Revisando el tipo de datos vectoriales
Es posible echar una mirada a los datos para averiguar qué tipo de datos están almacenados en el shapefile (puntos, líneas o polígonos) a través de la función .geom_type obteniendo este tipo de información.
0 LineString
1 LineString
2 LineString
3 LineString
4 LineString
...
1423 LineString
1424 LineString
1425 LineString
1426 LineString
1427 LineString
Length: 1428, dtype: objectDe manera similar a Pandas es posible que obtengamos información descriptiva sobre el GeoDataFrame usando .info(). Esto incluye el numero de filas y columnas, el nombre en la cabecera y el tipo de datos de cada columna.
<class 'geopandas.geodataframe.GeoDataFrame'>
RangeIndex: 1428 entries, 0 to 1427
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 scalerank 1428 non-null int64
1 featurecla 1428 non-null object
2 min_zoom 1428 non-null float64
3 geometry 1428 non-null geometry
dtypes: float64(1), geometry(1), int64(1), object(1)
memory usage: 44.8+ KBAbriendo un vector espacial de puntos
Ahora, se decargará un archivo de puntos de la principales ciudades del mundo:
# Descargamos un archivo vectorial de puntos
et.data.get_data(url='https://ndownloader.figshare.com/files/26266609')
# Creando la ruta hacia el shapefile
populated_places_path = os.path.join("data", "earthpy-downloads",
"ne_50m_populated_places_simple",
"ne_50m_populated_places_simple.shp")
# Abre el aarchivo y lee las 5 primeras filas de los datos
cities = gpd.read_file(populated_places_path)
cities.head()| scalerank | natscale | labelrank | featurecla | name | namepar | namealt | diffascii | nameascii | adm0cap | ... | rank_max | rank_min | geonameid | meganame | ls_name | ls_match | checkme | min_zoom | ne_id | geometry | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 10 | 1 | 5 | Admin-1 region capital | Bombo | None | None | 0 | Bombo | 0.0 | ... | 8 | 7 | 0.0 | None | None | 0 | 0 | 7.0 | 1159113923 | POINT (32.5333 0.5833) |
| 1 | 10 | 1 | 5 | Admin-1 region capital | Fort Portal | None | None | 0 | Fort Portal | 0.0 | ... | 7 | 7 | 233476.0 | None | None | 0 | 0 | 7.0 | 1159113959 | POINT (30.275 0.671) |
| 2 | 10 | 1 | 3 | Admin-1 region capital | Potenza | None | None | 0 | Potenza | 0.0 | ... | 8 | 8 | 3170027.0 | None | None | 0 | 0 | 7.0 | 1159117259 | POINT (15.799 40.642) |
| 3 | 10 | 1 | 3 | Admin-1 region capital | Campobasso | None | None | 0 | Campobasso | 0.0 | ... | 8 | 8 | 3180991.0 | None | None | 0 | 0 | 7.0 | 1159117283 | POINT (14.656 41.563) |
| 4 | 10 | 1 | 3 | Admin-1 region capital | Aosta | None | None | 0 | Aosta | 0.0 | ... | 7 | 7 | 3182997.0 | None | None | 0 | 0 | 7.0 | 1159117361 | POINT (7.315 45.737) |
5 rows × 39 columns
9.4 Creación de mapas usando múltiples archivos shapefile
Es posible crear mapas utilizando múltiples shapefiles con Geopandas de manera similar a cómo lo haríamos en programas con interfaz gráfica (GUI), como ArcGIS o QGIS. Para ello, es necesario contar con varios archivos geoespaciales. En el siguiente ejemplo, utilizaremos los datos descargados para generar un mapa.
Para graficar dos o más datasets juntos, es necesario crear un objeto de figura con Matplotlib. En el código que se muestra a continuación, se define la figura en ax1 en la primera línea. Si establecemos todos los datasets sobre el mismo Axes (ax=), le indicamos a Geopandas que sobreponga todas las capas, logrando así la composición esperada.
# Definimos la figura en ax1
f, ax1 = plt.subplots(figsize = (9, 6)) # Establecemos las dimensiones de la figura
# Indicamos a Geopandas que dibuje los datos en esa figura en particular
coastlines.plot(ax = ax1)
plt.show()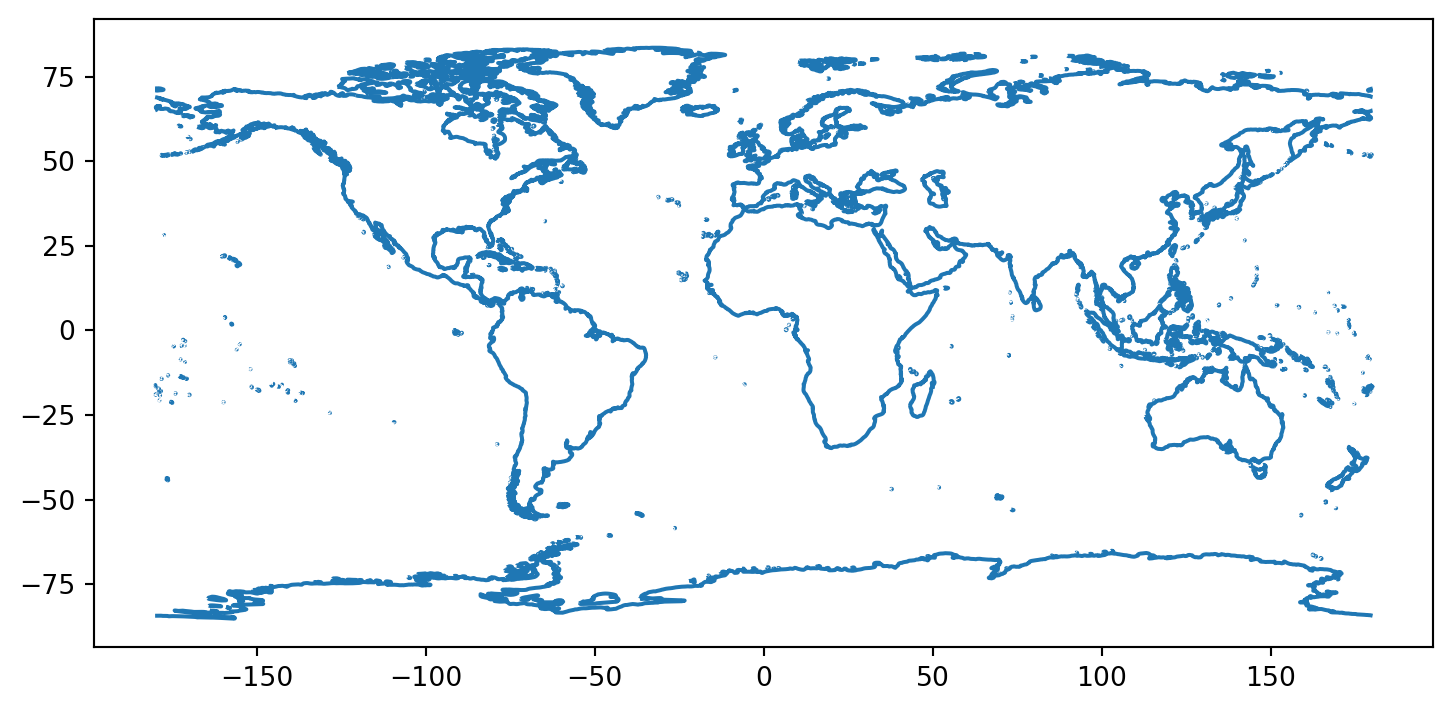
Si deseamos agregar otra capa, podemos hacerlo utilizando un segundo .plot(), pero especificando el mismo ax. Esto indica a Python que dibuje ambos datasets en la misma figura.
# Creando una figura con tres capas
f, ax1 = plt.subplots(figsize=(9, 6))
coastlines.plot(ax = ax1,
color = "black",
label = "Bordes Costeros") # se agrega una etiqueta a cada capa para la leyenda
boundary.plot(ax = ax1,
color = "red",
label = "Fronteras")
cities.plot(ax = ax1,
color = "orange",
label = "Ciudades")
# Agregamos un titulo
ax1.set(title = "Mapa de Ciudades y Lineas Costeras Escala Global")
# Agregamos una leyenda
ax1.legend()
plt.show()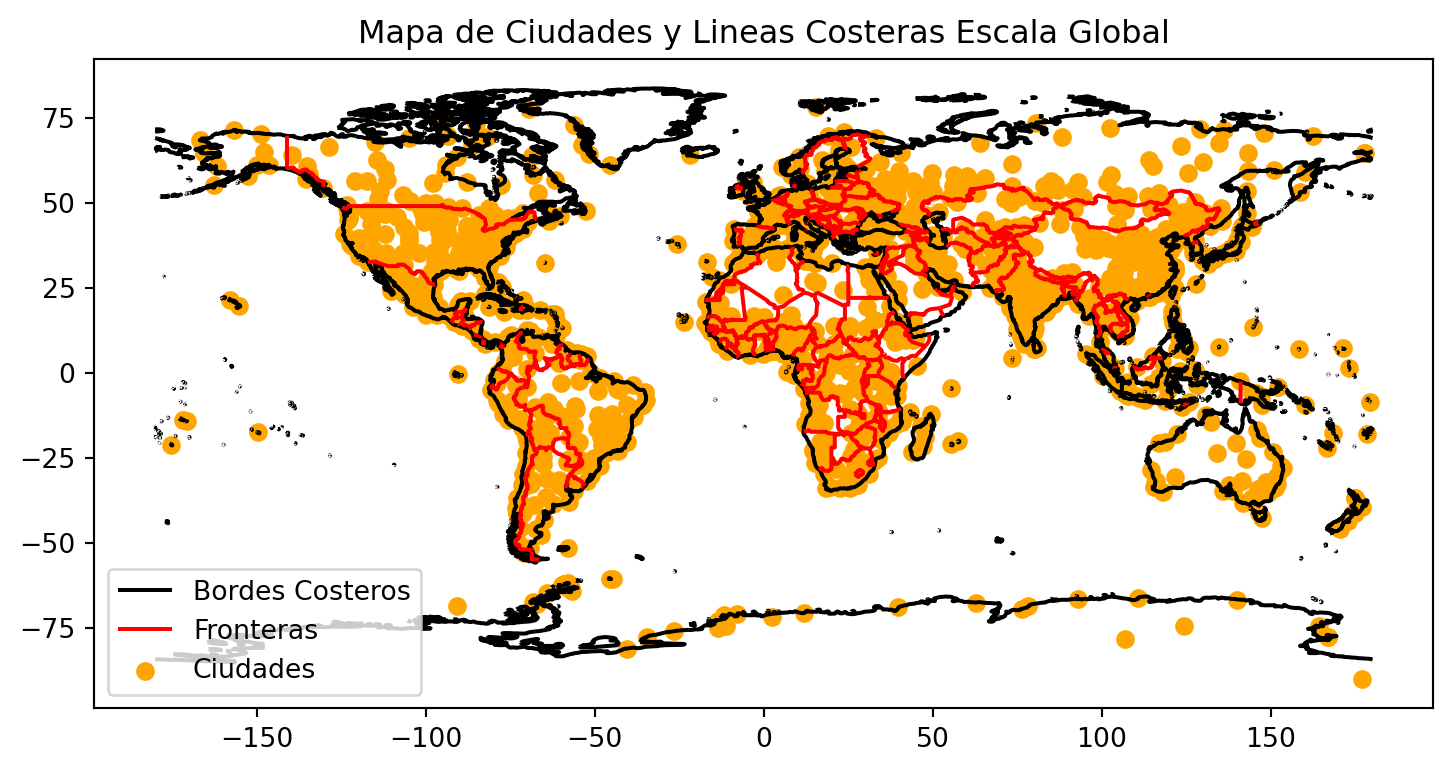
Es importante controlar los Axes. Si no se especifica la misma ax=, cada capa se dibujará en una figura diferente.
f, (ax1, ax2, ax3) = plt.subplots(ncols = 1,
nrows = 3)
coastlines.plot(ax = ax1,
color ="black")
cities.plot(ax = ax2,
color = "blue")
boundary.plot(ax = ax3,
color = "red")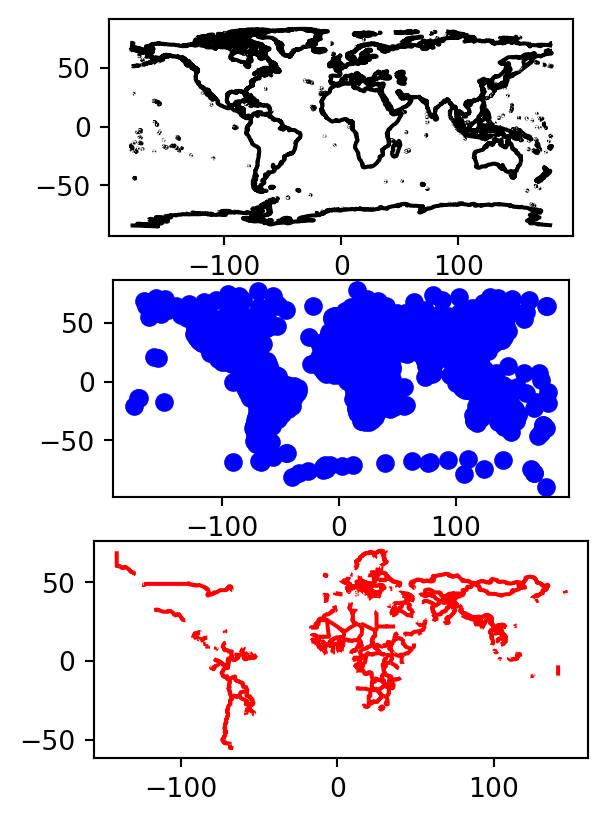
Atributos de los datos espaciales
Cada objeto en un shapefile tiene uno o más atributos asociados. Los atributos de los shapefiles son similares a los campos o columnas en las hojas de cálculo. Cada fila en una hoja de cálculo tiene un conjunto de columnas que describen ese elemento. En el caso de los shapefiles, cada fila representa un objeto espacial; por ejemplo, una carretera está representada por una línea en un shapefile de líneas, y tendrá una fila de atributos asociados.
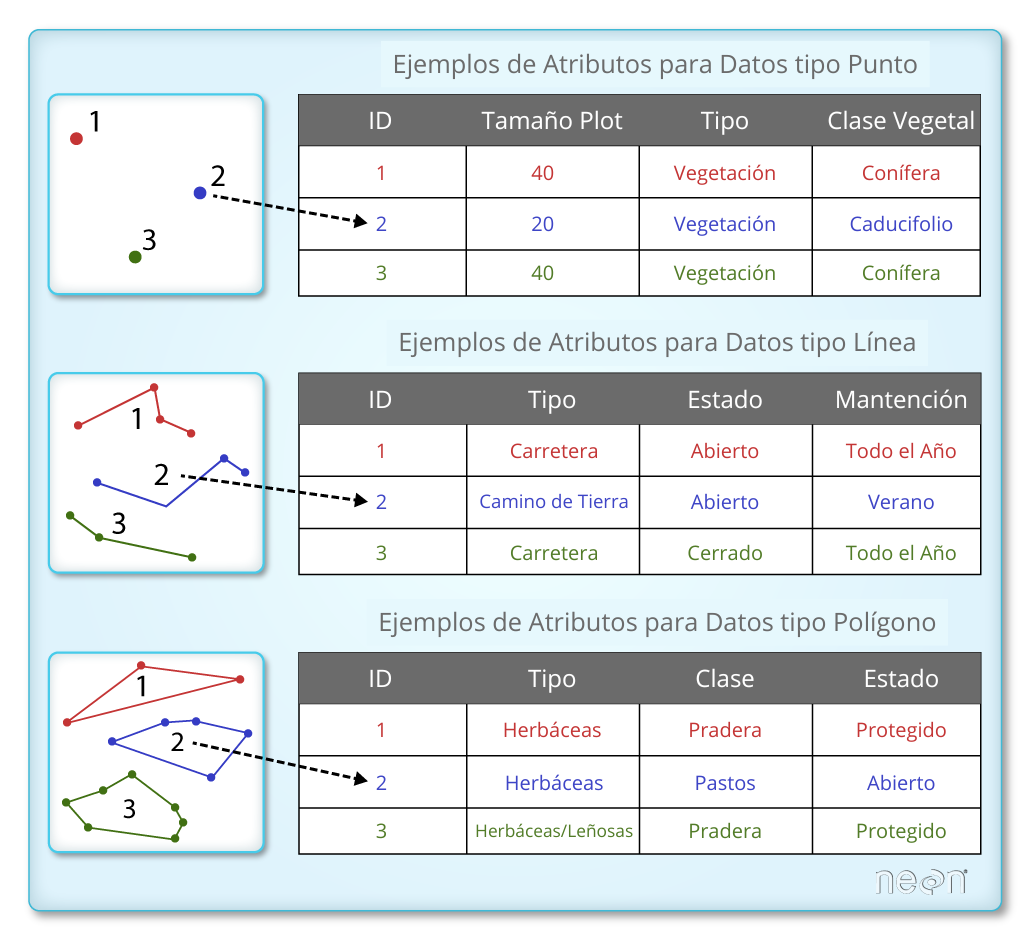
Los atributos de un shapefile importados en un GeoDataFrame pueden visualizarse directamente en dicho GeoDataFrame.
| scalerank | natscale | labelrank | featurecla | name | namepar | namealt | diffascii | nameascii | adm0cap | ... | rank_max | rank_min | geonameid | meganame | ls_name | ls_match | checkme | min_zoom | ne_id | geometry | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 10 | 1 | 5 | Admin-1 region capital | Bombo | None | None | 0 | Bombo | 0.0 | ... | 8 | 7 | 0.0 | None | None | 0 | 0 | 7.0 | 1159113923 | POINT (32.5333 0.5833) |
| 1 | 10 | 1 | 5 | Admin-1 region capital | Fort Portal | None | None | 0 | Fort Portal | 0.0 | ... | 7 | 7 | 233476.0 | None | None | 0 | 0 | 7.0 | 1159113959 | POINT (30.275 0.671) |
| 2 | 10 | 1 | 3 | Admin-1 region capital | Potenza | None | None | 0 | Potenza | 0.0 | ... | 8 | 8 | 3170027.0 | None | None | 0 | 0 | 7.0 | 1159117259 | POINT (15.799 40.642) |
| 3 | 10 | 1 | 3 | Admin-1 region capital | Campobasso | None | None | 0 | Campobasso | 0.0 | ... | 8 | 8 | 3180991.0 | None | None | 0 | 0 | 7.0 | 1159117283 | POINT (14.656 41.563) |
| 4 | 10 | 1 | 3 | Admin-1 region capital | Aosta | None | None | 0 | Aosta | 0.0 | ... | 7 | 7 | 3182997.0 | None | None | 0 | 0 | 7.0 | 1159117361 | POINT (7.315 45.737) |
5 rows × 39 columns
También es posible revisar únicamente los atributos que nos interesan. Revisemos cuales tiene cities.info():
<class 'geopandas.geodataframe.GeoDataFrame'>
RangeIndex: 1249 entries, 0 to 1248
Data columns (total 39 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 scalerank 1249 non-null int32
1 natscale 1249 non-null int32
2 labelrank 1249 non-null int32
3 featurecla 1249 non-null object
4 name 1249 non-null object
5 namepar 68 non-null object
6 namealt 201 non-null object
7 diffascii 1249 non-null int32
8 nameascii 1249 non-null object
9 adm0cap 1249 non-null float64
10 capalt 1249 non-null int32
11 capin 35 non-null object
12 worldcity 1249 non-null float64
13 megacity 1249 non-null int32
14 sov0name 1249 non-null object
15 sov_a3 1249 non-null object
16 adm0name 1249 non-null object
17 adm0_a3 1249 non-null object
18 adm1name 1162 non-null object
19 iso_a2 1249 non-null object
20 note 8 non-null object
21 latitude 1249 non-null float64
22 longitude 1249 non-null float64
23 changed 1249 non-null float64
24 namediff 1249 non-null int32
25 diffnote 512 non-null object
26 pop_max 1249 non-null int32
27 pop_min 1249 non-null int32
28 pop_other 1249 non-null int32
29 rank_max 1249 non-null int32
30 rank_min 1249 non-null int32
31 geonameid 1249 non-null float64
32 meganame 463 non-null object
33 ls_name 1223 non-null object
34 ls_match 1249 non-null int32
35 checkme 1249 non-null int32
36 min_zoom 1249 non-null float64
37 ne_id 1249 non-null int64
38 geometry 1249 non-null geometry
dtypes: float64(7), geometry(1), int32(14), int64(1), object(16)
memory usage: 312.4+ KBEn este caso solo nos interesa la columna de población máxima (pop_max).
Ayudantía
Disponible la ayudantía que contiene los ejercicios revisados en la clase: